









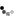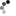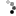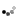 Рейтинг: 4.3/5.0 (1843 проголосовавших)
Рейтинг: 4.3/5.0 (1843 проголосовавших)Категория: Руководства

Фрагмент главной страницы сайта Membase
Иллюстрация с сайта Membase.Com
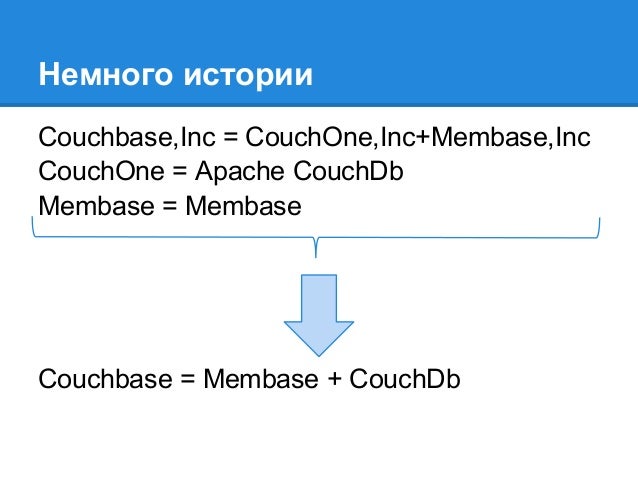
Сегодня CouchOne, стоящая за CouchDB, и Membase Inc, стоящая за одноименной NoSQL-БД, объявили о слиянии в компанию Couchbase, которая объединит специалистов по NoSQL в единую организационную структуру.
Руководство Couchbase «поделили» так: исполнительным директором (CEO) станет бывший глава Membase — Боб Видерхолд (Bob Wiederhold), а техническим директором (CTO) — Дэмиэн Катц (Damien Katz), бывший глава CouchOne.
Couchbase анонсирует весь спектр своих приложений и предложений, полученных в результате объединения решений CouchOne и Membase, в течение ближайших месяцев. На данный момент ожидается, что будут представлены:
Кстати, на момент написания новости сайт CouchOne был недоступен — по всей видимости, готовится его существенное обновление в связи с объединением компании с Membase. На сайте Membase главная страница уведомляет посетителей о произошедшем слиянии.
* Стоит напомнить, что еще в сентябре прошлого года Couchio, сменив название на CouchOne, заявляла о планах ориентировать свой бизнес на мобильное применение.















Спустя четыре месяца после первого превью разработчики Couchbase выпустили вторую версию Couchbase Server — документ-ориентированной NoSQL-СУБД с открытым исходным кодом. Объединив в себе функциональность key-value хранилища memcached и документ-ориентированной СУБД Apache CouchDB. новое решение представляет собой эдакое «два в одном».
Документы Couchbase создаются при помощи JSON-формата и являются в отличие от традиционных SQL-записей схемонезависимыми, что предоставляет разработчикам дополнительную гибкость при создании приложений, поскольку с данным типом БД нет необходимости заботиться о постоянно соответствии данных единой структуре БД. Индексирование и запросы к БД могут быть разделены среди множества Couchbase-серверов. Инкрементный MapReduce-фреймворк может использоваться с множеством разных типов запросов, а map и reduce функции создаются на тёплом ламповом JavaScript .
Облегчить разработчикам жизнь сможет разделение представлений данных. Представления могут создаваться как production и development, уменьшая объёмы обрабатываемых данных во втором случае. Couchbase Server 2 автоматически создаёт индексы, чтобы увеличить скорость работы map-функций, принимая во внимание тип представлений, с которыми ведётся работа.
Couchbase Server 2.0 доступен для загрузки в двух редакциях: Enterprise и Community. в 32 и 64-битных версиях для Ubuntu. Red Hat. Windows и Mac OS X. Кому нужны исходники — также имеются, но лишь для Community-версии. Enterprise версия подразумевает годичную подписку с поддержкой 24/7. Community-редакция распространяется на условиях Apache-лицензии и не рекомендуется к использованию в корпоративной среде.
Навигация по записямВас категорически приветствует автоматически сгенерированная почтовая рассылка с новостями от nixp.ru !
Вчера компания Zimbra, принадлежащая с прошлого года VMware, объявила о выпуске новой версии своего одноименного флагманского продукта — популярного Open Source-решения для групповой работы (groupware) Zimbra 7.
Zimbra — это комплексный программный продукт, предоставляющий ряд ключевых ИТ-сервисов для предприятий, таких как электронная почта, календари и контакты, обмен сообщениями, хранилище файлов и документов. При этом в Zimbra интегрирован целый комплекс популярного программного обеспечения с открытым кодом, среди которого, например, OpenLDAP, MySQL, nginx, Postfix, ClamAV, SpamAssassin, DSPAM, Lucene и другие.
Среди ключевых изменений в релизе Zimbra 7:
Ссылки на Open Source-редакцию Zimbra Collaboration Suite доступны здесь .
Фондовая биржа Йоханнесбурга (JSE, Johannesburg Stock Exchange), крупнейшего по населению города в ЮАР, последует примеру коллег из Лондона (LSE) и перейдет на Linux.
Сам случай миграции идентичен ситуации с фондовой биржей Лондона: с 2007 года в JSE используют платформу TradElect, использующую проприетарную инфраструктуру на базе Microsoft .NET и SQL Server 2000, а миграция будет осуществляться на платформу Millennium Exchange от шри-ланкийских разработчиков из компании MilleniumIT, которая, к слову, уже куплена LSE.
Впрочем, в переходе Йоханнесбурга есть и отличие от лондонской истории: в качестве операционной системы для запуска платформы Millennium Exchange будет использоваться только GNU/Linux (в LSE вдобавок к свободной ОС есть серверы с Solaris).
Ожидается, что перевод JSE на Millennium Exchange обеспечит очень значительный прирост в производительности при проведении торгов — транзакции будут выполняться почти в 400 раз быстрее, чем на нынешней платформе.
6 февраля Эван Мартин (Evan Martin) из компании Google анонсировал в своей блоге открытие исходного кода новой системы сборки Ninja, применяемой при разработке веб-браузера Chrome.
Как сообщает Мартин, на первых этапах портирования Chrome с Windows на другие операционные системы для сборки проекта на всех платформах в Google использовали Scons. Однако со временем было замечено, что, несмотря на все свои плюсы, Scons работает слишком медленно при сборке Chrome.
Мартин отдельно отмечает, что ни в коем случае не обвиняет Scons, поскольку случай Chrome (где часть кода — это куски движка WebKit) весьма специфичен. В итоге теперь для сборки Chrome используются Makefile-файлы «с набором умных хаков, большая часть идей для которых была почерпнута из системы сборки ядра Linux». Основная идея заключается в том, чтобы «заставить Make делать вещи, которые Make сам по себе не делает».
Так появилась система сборки Ninja, которая делает инкрементальную сборку Chrome примерно за 10-20 секунд. Её исходный код выложен на GitHub под свободной лицензией Apache License 2.0.
На походившей в конце января конференции по ИТ-безопасности ShmooCon 2011 представитель IBM X-Force Йон Лэример (Jon Larimer) выступил с докладом о потенциальной уязвимости в Linux из-за поддержки автоматически запускаемых приложений с USB-носителей.
Основная идея доклада — развеять миф о том, что операционная система GNU/Linux не подвержена атакам подобного рода (автозапуск с флешек — популярный способ распространения вирусов в Windows-системах на компьютерах с публичным доступом). Йон объясняет, какие атаки могут быть осуществлены, а в конце выдает рекомендации для Linux-поставщиков и конечных пользователей с тем, чтобы избежать проблем.
Видео с докладом «Autorun Vulnerabilities on Linux» доступно на YouTube .
Сегодня CouchOne, стоящая за CouchDB, и Membase Inc, стоящая за одноименной NoSQL-БД, объявили о слиянии в компанию Couchbase, которая объединит специалистов по NoSQL в единую организационную структуру.
Руководство Couchbase «поделили» так: исполнительным директором (CEO) станет бывший глава Membase — Боб Видерхолд (Bob Wiederhold), а техническим директором (CTO) — Дэмиэн Катц (Damien Katz), бывший глава CouchOne.
Couchbase анонсирует весь спектр своих приложений и предложений, полученных в результате объединения решений CouchOne и Membase, в течение ближайших месяцев. На данный момент ожидается, что будут представлены:
Кстати, на момент написания новости сайт CouchOne был недоступен — по всей видимости, готовится его существенное обновление в связи с объединением компании с Membase. На сайте Membase главная страница уведомляет посетителей о произошедшем слиянии.
* Стоит напомнить, что еще в сентябре прошлого года Couchio, сменив название на CouchOne, заявляла о планах ориентировать свой бизнес на мобильное применение.
Не забудьте, что мы всегда рады вашим комментариям к новостям непосредственно на nixp.ru !
Другие способы получения новостей от nixp.ru:
Блог компании centos-admin.ru.
NoSQL *
Жизнь системного администратора подкинула нового зверя на и без того тернистый путь. Потребовалось клиенту под проект в обязательном порядке использовать Couchbase.
Под катом инструкция по его установке, добавлению в кластер и балансировке данных. А вдруг кому будет полезно.
Скачиваем и устанавливаем couchbase 2.1.1
В нашей компании активно используется виртуализация OpenVZ, а для нормальной работы couchbase в контейнере openvz необходим файл memsup из пакета erlang-os-mon версии не ниже 2.2.10.
service couchbase-server stop
Для начала нужно скачать сам erlang, например, с официального сайта www.erlang.org/download.html
И скомпилировать нужную библиотеку, которая находится по пути lib/os_mon/priv
Затем, из lib/os_mon/priv/bin берем memsup и помещаем в каталог /opt/couchbase/lib/erlang/lib/os_mon-2.2.7/priv/bin/
Выставляем на него права:
chown bin:bin /opt/couchbase/lib/erlang/lib/os_mon-2.2.7/priv/bin/memsup
chmod a+x /opt/couchbase/lib/erlang/lib/os_mon-2.2.7/priv/bin/memsup
Запускаем сервер couchbase-server и пользуемся.
Админка по умолчанию доступна по hostname :8091/
Добавление нового сервера в кластер и балансировка данных.
Внимание!!! Перед добавлением нового сервера в кластер необходимо снять бэкап БД.
/opt/couchbase/bin/cbbackup -u Administrator -p PASSWORD http://localhost:8091/ /tmp/cbbackup/
Или, если нужен бэкап только одного бакета, остальные не важны:
/opt/couchbase/bin/cbbackup -u Administrator -p PASSWORD http://localhost:8091/ /tmp/cbbackup/ -b SRC_BUCKET
При добавлении нового сервера в кластер couchbase, необходимо сделать ребалансировку данных и может случиться так, что ребалансировка не проходит и в логе будет ошибка примерно такого содержания:
На hw ноде можно попробовать изменить vm.swappiness на время балансировки данных и повторно запустить ребалансировку:
sysctl -w vm.swappiness=0
Если балансировка не прошла:
Вариант 2. (Очищаем, либо удаляем бакет)
1. Смотрим через админку couchbase host :8091/ на каком бакете валится балансировка (вкладка Server Nodes и открываем сами сервера)
2. Идем на вкладку Data Bucket, открываем нужный бакет, а в нём кнопку (Edit)
3. Ищем в самом низу, рядом с кнопкой DELETE кнопку FLUSH. (Если её нет, чуть выше ставим галочку Flush-Enable.) И нажимаем FLUSH, тем самым очищаем содержимое бакета (Бэкап же у нас есть)
4. Если бакет очистился нормально, делаем снова ребалансировку. Если прошла то заливаем бакет назад.
/opt/couchbase/bin/cbrestore -u Administrator -p PASSWORD /tmp/cbbackup/ http://host:8091/ -b <_имя_бакета_>
5. Если бакет не очищается, либо если после очистки балансировка также не проходит на нем, то
6. В меню редактирования бакета (Edit) запоминаем (записываем) о нем всю информацию и удаляем его. После этого создаем новый с такими же параметрами и заливаем бэкап.
И так по каждому бакету.
И очень полезная команда, чаще всего приходится пользоваться:
/opt/couchbase/bin/cbrestore -u Administrator -p PASSWORD -b SRC_BUCKET -B DST_BUCKET -k "key1|key2|key3|key. |KeyN" /tmp/cbbackup/ http://localhost:8091
Восстанавливает отдельные ключи.
event 19 февраля 2014 в 01:03
Перевод ответа на stackoverflow.com на вопрос об отличиях CouchDB от Couchbase.
Я думаю есть несколько существенных отличий между CouchDB и Couchbase Server, которые необходимо отметить.
Я не буду писать о преимуществах перехода с CouchDB на Couchbase Server, потому, что они хорошо описаны везде (см. The Future of CouchDB by Damien Katz или Couchbase vs. Apache CouchDB by Couchbase). Вместо этого я постараюсь перечислить фичи CouchDB, которые вы не найдёте в Couchbase Server .
Названия и путаницаЕсть CouchDB, CouchIO, CouchOne, Couchbase, Couchbase Server, Couchbase Mobile, Couchbase Lite, CouchApps, BigCouch, Touchbase, Membase, Memcached, MemcacheDB. все разные и всё же связанные, очевидно, не только названиями.
Сначала была CouchDB, база данных, созданная Damien Katz, бывшим разработчиком IBM. Официальное название изменилось на Apache CouchDB после того, как она стала проектом Apache.
Компания под названием CouchIO была основана для работы над Apache CouchDB и позже изменила название на CouchOne (я имею ввиду название компании, а не базы данных).
CouchOne (бывшая CouchIO) объединилась с Membase (бывшая NorthScale), чтобы сформировать новую компанию под названием Couchbase. Membase (компания) разрабатывала Membase (продукт с таким же названием). Membase была создана несколькими лидерами проекта Memcached и использовала протокол Memcached. После объединения CouchOne и Membase, Couchbase продолжила разработку ПО Membase и позже изменило его название на Couchbase Server.
Сегодня, я думаю, большинство людей считает, что Couchbase Server это новая версия CouchDB, но на самом деле это новая версия Membase. Она всё ещё использует протокол Memcached и не использует REST API от CouchDB. Между тем CouchDB это всё ещё CouchDB, активно поддерживаемая и развивающаяся как проект Apache.
Теперь об отличиях:
ЛицензированиеCouchbase Server не полностью опенсорсное/свободное программное обеспечение. Есть две версии: Community Edition (свободная, но без последних исправлений ошибок) и Enterprise Edition (есть ограничения на использование, касающиеся конфиденциальности, аудитов от Couchbase Inc. которые "будут проводиться в обычное рабочее время на объектах Лицензиата" и другие условия, характерные для проприетарного ПО, которые многие люди могут счесть неприемлимыми).
CouchDB это опенсорсное/свободное программное обеспечение (без обязательств), проект The Apache Software Foundation и распространяемое по лицензии Apache License, Version 2.0 (DFSG-compatible, FSF-approved, OSI-approved, GPL-compatible, non-copyleft, commercial-friendly).
ФилософияЯ никогда не видел, чтобы на это указали прямо, но это, возможно, самое большое отличие между этими двумя базами данных потому, что это о философии моделей распределённых вычислений, а не только о некоторых особенностях, API или лицензировании. CouchDB и Couchbase Server совершенно разные в своих представлениях о построении распределённых систем и баз данных.
Согласно теореме CAP (consistency, availability, partition tolerance) - невозможно для распределённой базы данных одновременно обеспечивать согласованность данных, доступность и устойчивость к разделению.
CouchDB это система типа AP (обеспечивает доступность и устойчивость к разделению)
Couchbase Server это ИЛИ система типа CP (согласно Википедии) ИЛИ система типа CA (согласно техническому апдейту Couchbase) - ЧТО ИЗ ЭТОГО ПРАВИЛЬНО? ПРОКОММЕНТИРУЙТЕ, ПОЖАЛУЙСТА.
ОсобенностиВот, что я счёл необходимым указать из списка особенностей CouchDB, которые не поддерживаются в Couchbase Server:
Эти возможности CouchDB могут быть важны или не важны для вас, так что является ли их отсутствие недостатком или нет - строго субъективное мнение, но я думаю, что решение о том, переключаться с CouchDB на Couchbase Server или нет, должно основываться на этих различиях и том, зависите ли вы от этих возможностей в вашей текущей реализации на основе CouchDB.
Например, если вас заинтересовала CouchDB после просмотра изменений в CouchDB на NodeCamp, о которых рассказывал Mikeal Rodgers или один из уроков CouchApp от J. Chris Anderson, то вам стоит осозновать, что если вы хотите перейти на Couchbase Server, то вам придётся забыть о довольно многом из того, о чём они рассказывали.
Поэтому я бы сказал, что Couchbase Server выглядит как эволюзция Memcached и Membase (но не как эволюция CouchDB) и поэтому выглядит как хороший продукт если вы уже используете Memcached и Membase. Если вы используете CouchDB для самых простых задач, то вы можете рассматривать использование Couchbase Server для них и он, возможно, будет работать лучше (если вы не паритесь о лицензионных ограничениях). Но если вы пользуетесь какими-то функциями, которые уникальны в CouchDB (например, changes feed, CouchApps, двухуровневая архитектура, peer-to-peer репликация и т.д.), то вам стоит забыть о них, или остаться на CouchDB. В любом случае, убедитесь, что прочитали и поняли инструкцию по миграции на Couchbase для пользователей CouchDB до того, как будете думать о переходе.
У людей часто складывается неверное впечатление (возможно после прочтения чего-то вроде "Какое будущее у CouchDB? Будущее это Couchbase"), что CouchDB как-то устарел по сравнению с Couchbase Server, или что это старая версия Couchbase. Тем временем CouchDB активно развивающийся open-source проект, Couchbase Server это совершенно отдельный проект (это более новый проект, но это не новая версия CouchDB - они даже не совместимы) и поскольку даже новые инструменты для создания CouchApps всё ещё продолжают разрабатываться (например, Kanso project), то CouchDB никуда не исчезнет в ближайшее время.
Я надеюсь, что это внесёт ясность. Пожалуйста, исправьте меня, если я где-то неправ.
Обновление:Couchbase Server на самом деле новое название для Membase Server (он был переименован в Couchbase Server где-то в районе версии 1.8). Взгляните на обзор Couchbase 2011 года:
К сожалению, мы чертовски запутали многих наших пользователей. В дополнение к Membase Server и нашим новым мобильным продуктам мы также предложили Couchbase Single Server, который является собранным пакетом Apache CouchDB.
Кроме того, мы начали выпускать превью для разработчиков Couchbase Server 2.0, который включает технологию CouchDB в Membase Server - но этот продукт не был совместим с Couchbase Single Server (или CouchDB). [. ] Membase Server будет переименован в Couchbase Server 1.8 в следующем релиза в январе - небольшой шаг для того, чтобы облегчить путаницу с названием. Как и было запланировано в самом начале, релиз Couchbase Server 2.0 (на текущий момент Developer Preview 3) добавить функционал индекса и запроса. В то время как Couchbase Server 2.0 будет включать в себя существенную часть технологий из проекта CouchDB, он не будет иметь обратной совместимости с CouchDB и его не стоит рассматривать как "версию CouchDB".

Перевод итогов вебинаровCouchbase, которые на этой неделе опубликовал Perry Krug. Источник .
I just finished up a nine-week technical webinar series highlighting the features of our upcoming release of Couchbase Server 2.0. It was such a blast interacting with the hundreds of participants, and I was blown away by the level of excitement, engagement and anticipation for this new product.
Я (чит. - Пэри Круг ) только что закончил 9-недельную серию вебинаров, освещающих новые возможности предстоящего релиза Couchbase Server 2.0. Это были яркие беседы с сотнями участников и я просто обалдел от волнения, рассказывая о новом продукте и ожидая его выпуска.
(By the way, if you missed the series, all nine sessions are available for replay ).
(Если Вы пропустили серии, записи всех вебинаров находятся здесь ).
There were some great questions generated by users throughout the webinar series, and my original plan was to use this blog entry to highlight them all. I quickly realized there were too many to expect anyone to read through all of them, so I’ve taken a different tack. This blog will feature the most common/important/interesting questions and answer them here for everyone’s benefit. Before diving in, I’ll answer the question that was by far the most commonly asked: “How long until the GA of Couchbase Server 2.0?” We are currently on track to release it before the end of the year. In the meantime, please feel free to experiment with the Developer Preview that is already available. As for the rest of the questions, here goes!
Участники задавали хорошие вопросы и цель этого текста - собрать вопросы и ответы вместе, в этом блоге. Что я и сделал довольно быстро. Здесь будут освещены наиболее общие / важные / интересные вопросы и ответы на них. Но вначале, я отвечу на самый общий вопрос: "Когда появится официальная Couchbase Server 2.0?" Мы ожидаем её появления до конца года. Тем временем, пожалуйста, свободно эксперементируйте с версией для разработчиков. она уже доступна. Приступим!
Q: What are the primary benefits of incorporating Membase and CouchDB into a single product?
В> Какие основные преимущества включения Membase и CouchDB в один проект?
A: Membase is a super fast, highly scalable key value store known for its performance and scalability. CouchDB on the other hand is a great document database, with powerful indexing and querying capabilities. Combining these two products brings together the best of both worlds to create a high-performance, highly elastic NoSQL database that scales out linearly while providing querying, indexing and document-oriented features.
О> Membase - очень быстрое, масштабируемое хранилище "Ключ-Значение". CouchDB - великолепная документоориентированная база данных, с мощными возможностями индексации и построения выборок. Объединение этих двух продуктов позволяет создать высокопроизводительное, гибкое NoSQL-хранилище, обеспечивающее нас линейной сложностью при масштабировании плюс возможностями индексации и выборки документов.
Q: Does Couchbase speed up access to a database document by automatically caching it in memory?
В> Действительно ли увеличивается скорость работы с документами при кешировании данных в памяти?
A: Absolutely! That’s one of the great feature of Couchbase Server 2.0, and comes from the vast experience we have with memcached. All access to documents goes through our integrated RAM caching layer (built out of memcached) to provide extremely low and, more importantly, predictable, latency under extremely heavy loads. For instance, we regularly see customers well over 100k operations/sec across a cluster and have taken single nodes to over 200k operations/sec in our own testing environments. This RAM caching layer also allows us to handle spikes in write (and read) load without affecting the performance of the application.
О> Так и есть! Это одно из больших достижений Couchbase Server 2.0, и пришло оно благодаря нашему огромному опыту работы с Membase. Любой доступ к документам происходит через интегрированный кеш, RAM-слой (строится с помощью 'memcached'), что даёт крайне низкую и, что более важно, предсказуемую задержку в высоконагруженных системах. Например, мы сейчас получаем более чем 100K операций/сек на целом кластере, а в нашей тестовой среде смогли достичь производительности до 200K операций/сек для одного узла. Слой кеширования также позволяет нам обходить проблемы при записи (и чтении) без потери производительности приложения.
Q: I see in your forums that Couchbase Server 2.0 uses the memcached protocol for accessing data as this is compatible for existing Membase users and also for the much higher performance. Is there a way to use REST APIs akin to CouchDB’s to access the documents in Couchbase Server 2.0?
В> Я вижу на вашем форуме, что Couchbase Server 2.0 использует протокол memcached для доступа к данным для совместимости с уже существующими Membase-клиентами плюс для увеличения производительности. Как же тогда пользоваться REST API, который предоставляет CouchDB для доступа к документам?
A: The first version of Couchbase Server 2.0 uses the memcached protocol for document access, and the CouchDB HTTP protocol for accessing views. Over time, these two will merge even closer. In the meantime, we have provided a number of client libraries that abstract these two access methods away from the developer.
О> Первая версия Couchbase Server 2.0 использует memcached-протокол для доступа к документам и HTTP-протокол для доступа к представлениям CouchDB. Со временем это будет объединено. Пока что мы создали библиотеки, которые объединяют эти два метода доступа к данным.
Q: Is Couchbase Server 2.0 going to be open source?
В> Couchbase Server 2.0 будет OpenSource-проектом?
A: It already is! As a company, Couchbase is fully committed to the furthering of the open source communities that exist and are being built around our various products. While our focus is on providing enterprise-class software to our paying customers, we embrace the free-flow of ideas and wide adoption that an open source project allows for and believe very strongly that there is a place for both.
О> Он уже им является! Как организация, Couchbase полностью представлена в сообществе OpenSource и на основе Couchbase Server 2.0 могут создаваться свои вариации продукта. Несмотря на то, что мы сосредоточены на приложениях класса предприятия, мы открыты для идей и верим, что благодаря OpenSource система будет адаптирована и для других областей.
Indexing/Querying
Индексация / Выборка
Q: All I need is a simple secondary index, not map/reduce. how do I do that?
В> Всё что мне нужно, это просто вторичный индекс, не map/reduce. Как мне быть?
A: Currently, all of our indexes are built using a map function (the reduce is totally optional and can be ignored here). This is really just another syntax for creating an index and there are a variety of examples avialable discussing how to create very simple indexes. The very simplest form would involve just putting "emit(doc. )" in your map function where is what you want to index off of. This will create a list of all documents containing that field, sorted by that field. Of course there are more complex scenarios, but it can be made quite simple if that is what is needed.
О> В настоящее время все индексы строятся используя map-функцию (reduce можно игнорировать). Это просто другой синтаксис для создания индекса и есть множество разных примеров, как создать очень простые индексы. Самое простое - поместить emit( doc.field ) в Вашу map-функцию. Это создаст список всех документов, содержащих поле 'field'; список будет сразу отсортирован по этому полю. Конечно, в действительности приходится сталкиваться с более сложными сценариями, но строится индекс всегда очень просто, если знаете, что Вам нужно.
Q: How does dealing with Couchbase Server 2.0 views differ from CouchDB and Couchbase Single Server?
В> Чем представления Couchbase Server 2.0 отличаются от CouchDB и Couchbase Single Server?
A: Not at all. the format, the syntax, everything is the same. Additionally, all the options for querying are supported. You can literally copy-paste the view code from one to another. Multiple design docs are also supported.
О> Ничем. Формат, синтаксис, всё остальное - одинаково. В дополнение, все опции запросов поддерживаются. Вы можете буквально копировать код представления из одной системы в другую. Множество дизайн-документов также поддерживается.
Q: Does Couchbase Server 2.0 support ad-hoc querying?
В> Couchbase Server 2.0 поддерживает запросы по требованию (ad-hoc запросы)?
A: At the moment, all querying to Couchbase Server (like CouchDB) must be done against pre-materialized views. In general, this is the only way of providing reliable performance when making those queries. We also understand the need to for more on-demand/ad-hoc querying and are working diligently to provide that as well. Couchbase has already begun to take an industry-leader approach to creating a language specifically for unstructured data that can be used across the NoSQL landscape. Take a look at http://unqlspec.org to see what we're working on!
О> В данный момент все запросы к Couchbase Server (аналогично - к CouchDB) должны быть предварительно воплощены в представлениях. В общем, это только способ получить надёжную работу этих запросов. Мы также понимаем необходимость создания запросов по требованию и старательно работаем, чтобы это тоже было. Couchbase уже начали воспринимать как отраслевого лидера, создающего язык специально для работы с неструктурированными данными. Взгляните по http://unqlspec.org - и увидите, что работы идут полным ходом!
SDKs/Client Libraries
Среды разработки / Клиентские библиотеки
Q: Which SDK's and client libraries are supported?
В> Какие SDK и клиентские библиотеки поддерживаются?
A: At a base level, Couchbase Server 2.0 supports any library that implements the memcached protocol (and there are MANY of those). For the additional functionality that we have added (extended protocol commands and view access) Couchbase provides client libraries for a variety of languages (Java. NET, PHP, Python, Ruby, C/C++) as well as instructions for how to extend libraries for other languages.
О> На базовом уровне, Couchbase Server 2.0 поддерживаются библиотеки, которые реализуют протокол Memcached (и таких много). Для расширения функциональности, мы добавили библиотеки на разных языках программирования (Java. NET, PHP, Python, Ruby, C/C++) а также руководства, как создать библиотеку на других языках.
Q: Is there any chance of dogpiling with stale=update_after? If you get 30 requests simultaneously for a view with stale=update_after, will they generate several requests simultaneously for updating the index?
В> Есть возможность создать беспорядок при использовании stale=update_after? Если вы получаете одновременно 30 запросов для обновления с включённым stale=update_after, тогда будут генерироваться разные запросы при обновлении индекса?
A: To recap, “stale” tells the server that this query request should be returned as quickly as possible, knowing that some data that has already been written may not be included in the view. By putting “update_after” in the request as well, the client is telling the server to rematerialize the index in the background…after returning the initial request as quickly as possible. Once this rematerialization is started, subsequent requests will not cause anything different to happen so there’s no worry of “dogpiling” or “stampeding herd” issues.
О> Вспомним, 'stale' говорит серверу что ответ на этот запрос должен быть возвращён так быстро, насколько возможно. Это означает, что некоторые данные, которые были записаны в хранилище, могут не попасть в представление. Поставив 'update_after' в запрос, клиент говорит серверу перестраивать индекс в фоне. после возвращения начального запроса так быстро, насколько возможно. Раз построение индекса началось, последующие запросы не вызовут ничего. Так что не волнуйтесь о беспорядке в базе (в ориг. - dogpilling or stampeding herd, "собачей кучи" или "панического бегства стада").
Q: How does the client know when to pull updated the server/vbucket maps?
В> Как клиент узнает, что обновление на сервере завершилось?
A: All clients (whether they be our “smart” clients or are going through our Moxi process) will maintain a streaming connection to a Couchbase Server. When the topology of the cluster changes (add/remove/failover nodes), the clients will be automatically updated with a new vbucket map over this connection. The clients can also request this map on-demand, and do so everytime they startup. Additionally, each node of the cluster knows which vbuckets it is responsible for and will only return data for those vbuckets. This way, even if a client is temporarily out of sync with the cluster, it will never be vulnerable to inconsistent data.
О> Все клиенты (будь это наши "умные" клиенты или идущие через наш Moxi -процесс) будут поддерживать потоковое соединение с Couchbase Server. Когда топология кластера изменится (добавятся / удалятся / откажут узлы), клиент будет автоматически извещён по этому соединению получение новой vbucket -карты. Клиенты также могут самостоятельно отправить запрос этой карты и делать это каждый раз при подключении. Кроме того, каждый узел кластера знает какие vbacket за что отвечают и может вернуть данные для конкретных vbucket. Т.о. даже если клиент временно не синхронизирован с кластером, он никогда не будет уязвим к получению противоречивых данных.
Development/Production View Usage
Использование представлений при разработке / в производстве
Q: Why the extra effort of creating a view in “development” mode and then pushing it to production?
В> Почему нужны дополнительные усилия для создания представлений в режиме "разработки" и когда внедряем представления на стадии "производства"?
A: We wanted to provide the ability to do view development on a live dataset, but didn’t want to have that development impact the currently running application. Thus, a “development” mode was created so that users could create and edit views on “real” data. In order to speed up the iterations of development, the default is to materialize a view over a subset of the data. When the development is complete, the user can opt to materialize the view over the whole cluster right before pushing it to production. This gives the added benefit of materializing the view so that it is immediately ready for the application to use. Lastly, this “development” mode can be used to edit views that are currently in production. without affecting the application’s access to them (by making a copy). When the edits are complete, the view can then be materialized and swapped with the original into production.
О> Мы хотели бы предоставить возможность строить представления на живых наборах данных, но не хотим влиять при разработке на работающее сейчас приложение. Т.о. режим "разработки" был создан: так пользователи могли бы создавать и редактировать представления на "реальных" данных. В целях ускорения итераций разработки, по умолчанию представления создаются над подмножеством данных. Когда разработка завершена, пользователь может разместить представление на целом кластере прямо перед запуском на живых данных. Это даёт дополнительное преимущество: представление готово к немедленному использованию в приложении. Наконец, этот режим "разработки" может быть использован для редактирования представлений, находящихся в "производстве", без затрагивания самого приложения (сделав копию). Когда редактирование завершено, новое представление может заменить оригинал на "производстве".
Q: How do you control what the development data set is?
В> Как контролировать, что работаем с "данными для разработки"?
A: Currently, the development dataset is automatically decided by the software depending on how much data exists. For small datasets, the software will actually materialize the view across the whole thing. As that gets larger, the software will automatically scale it down to provide a quicker response time while developing. Once the view is finalized, the user has the option to run it over the whole dataset manually (by clicking the tab “Full Cluster Dataset”) both for the purposes of final verification and to prepare it for production use.
О> На сегодня, набор данных для разработки автоматически определяется приложением в зависимости от объёма существующих данных. Для малых наборов, приложение будет создавать представление, включив все данные. Для больших наборов, приложение автоматически масштабирует наборы, опираясь на время отклика при их получении. По завершении разработки представления, пользователь имеет возможность вручную запустить код для всего набора (щёлкнув по вкладке "Full Cluster Dataset") с целью окончательной проверки и подготовки представления для использования в "производстве".
Q: For a bucket with replica and auto-failover, will a server failure without rebalance causing retrieval/update errors on that bucket?
В> Для пакета (bucket) с репликой и при включённой "автоматической отказоусточивости", сбой пройдёт без перебалансировки кластера в случае ошибки выборки / обновления в пакете?
A: When a server initially fails (for whatever reason: hardware, network, software) the application will briefly get errors for any data which that server was responsible for. Requests for data on other servers will not be impacted. These errors will continue until the node is “failed over” which activates the replica data (vbuckets) elsewhere in the cluster. The amount of time will vary depending on whether you are using automatic or manual failover… but once the failover is triggered there is no more delay. You might ask “but why can’t I read from the replica data that already exists.” The answer is two-fold. First, we specifically disallow access to the replica data (while it is “replica”) to preserve the very strong consistency that our system provides. Under normal operation, you are guaranteed to “read your own writes” and this is done by only providing one location for accessing any given piece of data. By allowing unrestricted reading of replicas, you might have a situation where one client writes a piece of data to the active copy and another client immediately tries to read that data from the replica…leading to possible inconsistency. Now, the second part of this answer is that we are currently working on feature to allow for reading from these replicas. It will be a new operation that is explicitly invoked by the application so that there won’t be any confusion about which copy is being read from. You’ll still want to failover the node as quickly as possible since writes will continue to fail. This is one example of the many features we have added as a direct response to our customers’ and users’ demands…you speak, and we listen (and then do something about it too)!
О> Когда произошёл сбой на сервере (по любой причине: оборудование, сеть, программа) приложение будет получать ошибки при запросе любых данных с этого сервера. Запрошенные с других серверов данные останутся прежними. Эти ошибки будут идти до узла, который активировал репликацию данных (vbuckets). Продолжительность будет варьироваться в зависимости от использованного режима отказоустойчивости - ручного или автоматического. Вы можете спросить: "Но почему я не могу прочесть данные из реплики, которая уже существует?" Ответ складывается из двух частей. Во-первых, мы специально запретили доступ к реплике, чтобы сохранить строгую согласованность данных в нашей системе. При нормальной работе вам гарантируется возможность "читать собственные данные". Позволив неограниченное чтение реплик, можно получить ситуацию, когда один клиент записывает часть данных в активную копию, а другой в это же время пытается прочитать данные из реплики. что, возможно, приведёт к несогласованности. Вторая часть ответа касается возможности чтения из этих реплик. Это должна быть новая операция, в которой приложение ясно говорит, что прочитанные данные не внесут путаницы в работу. Вы до сих пор получаете быстрый отказоустойчивый узел, но запись в него вызовет сбой. Это лишь один пример, как много возможностей мы добавили, выслушав наших заказчиков и пользователей. Вы говорите, мы слушаем (и делаем)!
Q: Is there any effect/risk/time when rebalancing a system under heavy write loads? Is it best to add nodes during quite times?
В> Действия / риски / время при восстановлении равновесия (перебалансировки) системы при большом частоте записей в неё.
A: By design, the rebalance operation is done asynchronously so as to have as minimal-as-possible an impact on the performance of the cluster. However, the reality is that rebalancing puts an increased load on the cluster and requires resources in order to do so (network, disk, RAM, CPU). If the cluster is already close to capacity, any increased load may impact the application’s performance. While safe to do at anytime, we highly recommend performing your own tests in your own environment to characterize what, if any, impact will be had by a rebalance. Typically our customers perform these at low or quiet times, but the main advantage is that you don’t need to take the application completely offline as you continue to scale.
О> По замыслу, операция перебалансировки производится асинхронно, так что имеем минимальное влияние на производительность кластера. Однако, в реальности перебалансировка увеличивает нагрузку на кластер и требует ресурсов (сеть, диск, память, процессор). Если кластер уже наполнен до отказа, любая загрузка в него может влиять на производительность приложения. Хотя это безопасно, мы очень рекомендуем провести свои собственные тесты, чтобы определить степень влияния перебалансировки на вашу систему. Обычно наши клиенты уделяют этому вопросу мало времени, но основное преимущество перебалансировки - вам не нужно останавливать работу системы, чтобы ускорить её работу.
Q: What’s a vbucket?
В> Что такое vbucket?
A: A vbucket is our way of logically partitioning data so that it can be spread across all the nodes within a cluster. Every Couchbase-type bucket that gets created on the cluster is automatically (and transparently) split up into a static set of slices (the vbuckets). These are then “mapped” to individual servers. When a node is added or removed, it is these slices that get moved around and re-mapped to provide linear and non-disruptive scaling. While totally abstracted from the application and user, it’s important to realize that vbuckets exist “under-the-hood” to provide much of the wonderful capabilities that Couchbase Server has. You can learn more about the vbucket concept here: http://www.couchbase.org/wiki/display/membase/vBuckets
О> vbucket - это наш вариант логического деления данных, которые могут передаваться между узлами кластера. Каждый пакет (bucket) в кластере автоматически (и прозрачно) разбивает наборы данных на куски (vbucket). Пакеты затем "проецируются" на отдельные серверы. Когда узел добавляется или убирается, части данных перемещаются и перепроецируются. Это происходит без прерывания работы системы. Пакеты не затрагивают приложение и пользователя. Вы можете узнать больше о концепции vbucket здесь > http://www.couchbase.org/wiki/display/membase/vBuckets
Q: Is the Couchbase Server Web UI the only method of monitoring a Couchbase Server cluster?
В> Веб-интерфейс Couchbase Server - единственный способ наблюдать за работой кластера?
A: Not necessarily, no. All that you see and can do in the Web UI is actually driven by our REST interface (http://www.couchbase.org/wiki/display/membase/Membase+Management+REST+API ) that is programmatically accessible externally. Additionally, each individual server (and each individual bucket on that server) provides its own “raw” statistics that are used by the REST API. These raw statistics are available externally as well: http://www.couchbase.org/wiki/display/membase/Monitoring+Membase. It is our goal to provide as much information as possible about the system so that our users can effectively monitor it both from a capacity planning perspective and a diagnostic/troubleshooting perspective when things start to go wrong (or to prevent things from going wrong in the first place.
О> Вовсе нет. Всё, что вы видите и можете делать в веб-интерфейсе Couchbase Server, управляется нашим REST-интерфейсом. доступным внешним программам. Также, каждый конкретный сервер (и каждый конкретный пакет на сервере) предоставляет по REST API собственную "сырую" статистику. Эта сырая статистика также доступна извне. Наша цель - предоставить информацию о системе так много, насколько возможно, чтобы наши пользователи могли эффективно наблюдать работу кластера, планирую т.о. наращивание мощностей и диагностирую/исправляя проблемы, как только они возникнут (или предупреждать их возниконовение).
Q: What kind of alerting does Couchbase Server provide?
В> Какие виды оповещения предоставляет Couchbase Server?
A: Technically, we are not a company that makes alerting software. In our minds, our job is to provide an interface for other systems to make use of. Most larger organizations would not want each piece of technology in their stack sending out a differently formatted set of alerts. That is why we have made it so easy to plug our statistics and monitoring data into any other system. However, we also realize that some smaller environments may in fact want our software to provide this out of the box. We are working on extending our capabilities here and already provide alerts for when nodes go down.
О> Технически, мы не компания, что создаёт приложения для оповещения. По нашему мнению, наша работа - предоставить интерфейс для других систем. Большинство организаций не хотят собирать по кусочкам оповещения, отправленные в разных форматах. Однако, мы реализуем небольшую среду окружения, которая может использоваться "из коробки" (без необходимости подключения других приложений). Мы работаем над расширением возможностей и уже передаём оповещения об узлах, которые "упали".
Autocompaction
Автоматическое сжатие
Q: If you abort the compaction at the end of the timeperiod, is the compaction done up until that point still saved or is all compaction done thus far lost?
В> Если прервать процесс сжатия базы, последующий запуск сжатия продолжится с сохранённой точки или начнётся сначала?
A: Normally, a compaction is all-or-nothing and so aborting it will lose the progress that has been made so far. However, within Couchbase Server, we are performing the compaction on a per-vbucket (see above) basis and so the whole dataset can actually be compacted incrementally without losing all of the progress it has made when aborted.
О> Нормально, когда сжатие проходит по принципу "всё или ничего" и прерывание сжатия приводит к необходимости начать его сначала. Однако, с Couchbase Server мы выполняем сжатие по пакетам (vbucket, см. выше) и целый набор данных в действительности сжимается инкрементно, без потери прогресса в случае отмены сжатия.
Autofailover
Автоматическая отказоустойчивость
Q: Why is a delay imposed before the cluster will automatically failover a downed node?
В> Почему введена задержка до того как кластер автоматически отключит упавший узел?
A: By default, the software is configured with a 30-second minimum before automatic failover will kick in. This is designed to prevent the software from doing the “wrong thing”. For example, if a node is simply slow to respond, or there is a brief network hiccup, you wouldn’t want it to be failed over and so the cluster will wait to ensure that the node is actually down. There are a few other situations to be taken into consideration and you can read more about these and our design decisions to handle them here.
О> По умолчанию, приложение сконфигурировано с 30-секундным минимум до автоматического исправления проблемы. Это защищает приложение от "неправильного поведения". Например, если узел просто медленно отвечает или в сети небольшой сбой, вы не хотите получить сигнал об ошибке и поэтому кластер будет ждать, чтобы быть уверенным, что узел действительно упал. Существует и несколько других ситуаций, достойных рассмотрения и вы можете прочитать больше о них и о наших проектных решения здесь.
To get even more information, you can view the 25-30 minute videos of each week's webinar by going here. And the authoritative place for all information regarding Couchbase Server 2.0 can be found here. While this series may have come to a conclusion, we are already planning on starting up another one to highlight not only the features of Couchbase Server 2.0, but also Couchbase Mobile, our SDKs/client libraries and more! Some of the topics will include:
To make it even better, I'm asking you to help participate! Please comment here (or send me an email directly at perry@couchbase.com ) with any topics that think we need to cover more and we’ll do our best to include them in an upcoming webinar.
Чтобы сделать это лучше, я прошу вас помочь своим участием! Пожалуйста, комментируйте здесь (или отправьте email на perry@couchbase.com ) с любой темой, которую, думаете, надо раскрыть больше - и мы сделаем всё возможное, чтобы включить их в предстоящий вебинар.






