




 Рейтинг: 4.2/5.0 (1818 проголосовавших)
Рейтинг: 4.2/5.0 (1818 проголосовавших)Категория: Бланки/Образцы
2. Включите сканер.
3.Запустите программу FineReader Forms (Пуск > Программы > ABBYY FineReader > Fine Reader 4.0 Forms).
4. Откройте крышку сканера, положите бланк на окно сканера текстом вниз, закройте крышку.
5. Дайте команду Файл > Новый.
6. Задайте имя пакета и место его размещения, после чего щелкните на кнопке Далее.
7. Установите переключатель Создать новый и щелкните на кнопке Далее.
8. Введите имя шаблона и щелкните на кнопке Далее.
9. Установите переключатель Отсканировать и щелкните на кнопке Далее. Дождитесь окончания сканирования. Щелкните на кнопке Готово.
10.Создайте блоки, охватывающие постоянные поля («разметку») бланка. Для каждого такого блока на вкладке Блок диалогового окна параметры задайте тип Статический.
10.Создайте блоки, охватывающие переменные (заполняемые) поля бланка. Для каждого такого поля установите флажок Экспортируемый блок и задайте имя поля базы данных (Поле БД).
11.Завершив разметку бланка, щелкните на кнопке Закрыть на панели инструментов.
12.После закрытия редактора шаблонов снова отсканируйте тот же бланк, но уже для распознавания (кнопка Сканировать на панели инструментов Open&Read).
13.Щелкните на кнопке Наложить шаблон на панели инструментов Open&Read.
14.Щелкните на кнопке Распознать на панели инструментов Open&Read.
15.Ознакомьтесь с заполненной формой, полученной в результате распознавания. Сохраните документ в виде таблицы Excel.
Мы научились обрабатывать бланки, имеющие предопределенную структуру. Мы также узнали, как сохранять результаты распознавания в виде, удобном для дальнейшей обработки.
















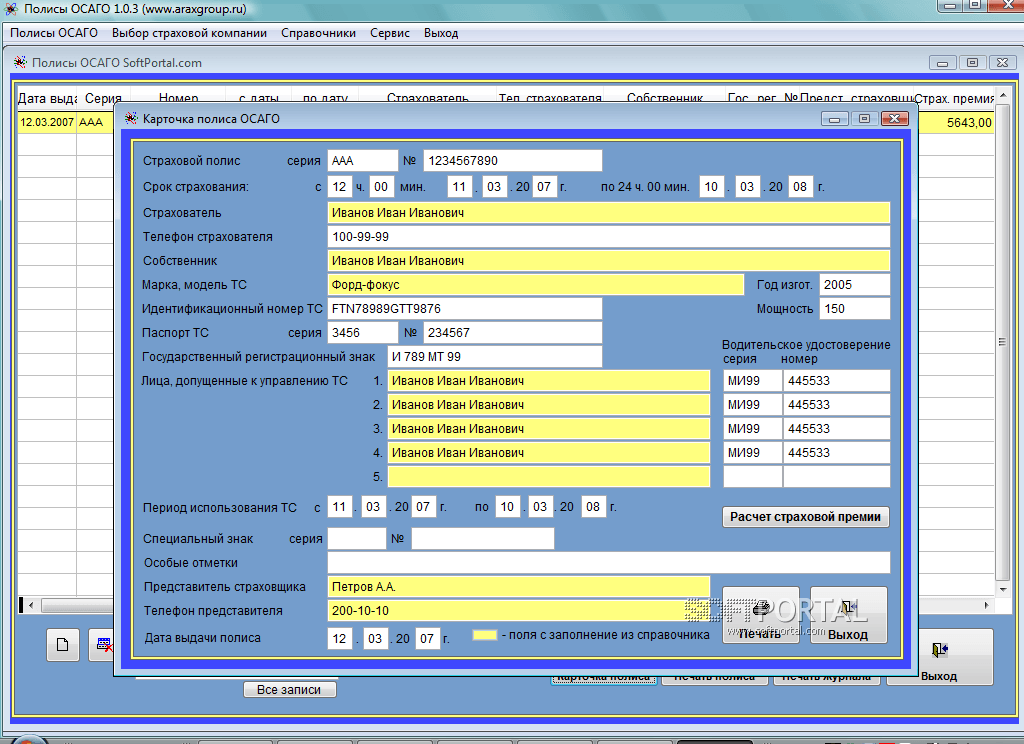
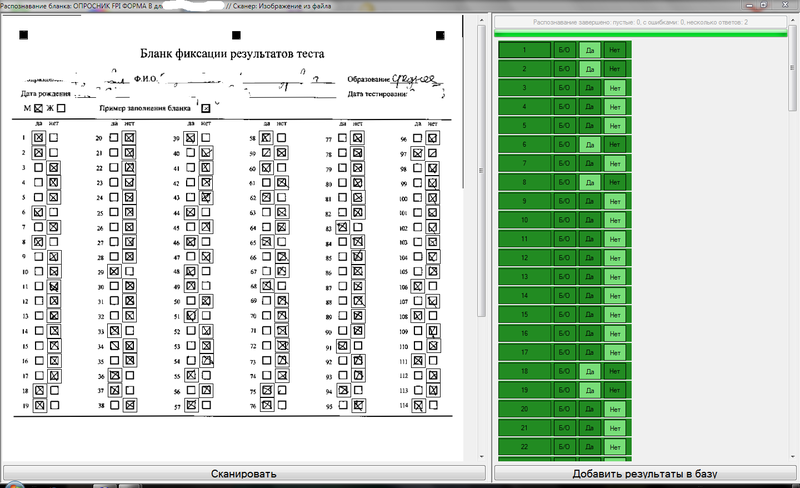
Бланки, или формы, представляют собой особый род документов. Они используются как анкеты, бюллетени для голосования, опросные листы и состоят из постоянной части, содержащей информацию, используемую в ходе заполнения бланка, и переменной части, куда при заполнении бланка заносятся данные. В ходе обработки бланков требуется получить внесенные в него данные и представить их в виде, удобном для дальнейшей обработки. При этом часто приходится иметь дело с тысячами однотипных бланков.
Для обработки бланков используется автономное приложение FineReader Forms. Процесс работы с бланками несколько отличается от работы с обычными документами. Вначале подготавливается шаблон, который содержит все постоянные и переменные зоны бланка. Этап сегментации заменяется наложением шаблона, то есть его совмещением с постоянными элементами бланка. Это позволяет определить местонахождение переменных элементов бланка и провести их распознавание. Данные, полученные с отдельного бланка, рассматриваются как строка таблицы или как отдельная запись базы данных. Содержимое отдельного поля бланка соответствует ячейке таблицы.
Для создания шаблона требуется электронное изображение отдельного бланка, хотя бы и незаполненного. Чтобы создать шаблон, надо в приложении FineReader Forms дать команду Файл > Новый, после чего указать имя пакета форм и папку для хранения отсканированных бланков. Затем необходимо отсканировать или выбрать готовое изображение, которое будет использоваться в качестве основы шаблона.
Сам процесс создания шаблона состоит в ручной сегментации бланка. При этом кроме окна Редактор шаблонов открыто также диалоговое окно Параметры. Следует определить как блоки, охватывающие фиксированные элементы бланка, так и те, которые содержат области, подлежащие заполнению. Блоки, соответствующие постоянным элементам, используются как приводные метки. Чтобы исключить такой блок из процесса распознавания, следует щелкнуть на нем правой кнопкой мыши и выбрать в контекстном меню команду Тип блока > Статический текст.
Параметры блока задают на вкладке Блок диалогового окна Параметры. Для каждого распознаваемого блока надо установить флажок Экспортируемый блок, а также указать имя поля базы данных. Информация из этого блока будет заноситься в указанное поле. После того как все нужные блоки созданы и настроены, следует щелкнуть на кнопке Закрыть на панели инструментов. При этом производится проверка, обеспечивают ли заданные блоки возможность однозначного наложения шаблона на бланк.
В результате сканирования заполненного бланка, наложения шаблона и распознавания, полученные данные представляются в виде формы, содержащей названия полей и данные, полученные при распознавании. Сохранение данных производят в формате, ориентированном на последующую обработку средствами электронных таблиц или баз данных, например, в виде электронной таблицы Excel (файл .XLS).
Практическое занятие
Упражнение 17.1. Сканирование документа
Запустите программу Imaging (Пуск > Программы > Стандартные > Imaging).
Откройте крышку сканера, положите документ на окно сканера текстом вниз, закройте крышку.
Дайте команду Файл > Сканировать.
Средствами открывшегося диалогового окна драйвера ТТВД/ЛГ проведите предварительное сканирование документа.
Средствами диалогового окна драйвера ТТОД/ЛГ выделите на документе область, подлежащую сканированию.
Средствами диалогового окна драйвера TWAIN задайте черно-белый режим и разрешение сканирования.
Средствами диалогового окна драйвера TWAIN проведите сканирование.
Закройте диалоговое окно драйвера TWAIN.
Ознакомьтесь с тем, как выглядит отсканированный документ. Увеличьте масштаб изображения, чтобы оценить качество воспроизведения отдельных символов.
Сохраните отсканированный документ в формате TIFFдля использования в следующем упражнении.
Запустите программу FineReader (Пуск > Программы > ABBYY FineReader > Fine Reader 4.0 Professional).
Откройте крышку сканера, положите документ на окно сканера текстом вниз, закройте крышку сканера.
Щелкните на кнопке Сканировать на панели инструментов Scan&Read.
Дождитесь окончания сканирования. Обратите внимание на появление значка отсканированного документа на панели Пакет и окна Изображение.
Щелкните на кнопке Сегментировать на панели инструментов Scan&Read. Изучите результат автоматической сегментации.
Щелкните на кнопке Распознать. Ознакомьтесь с распознанным текстом в окне Текст.
Сохраните распознанный текст в виде текстового файла.
Откройте текстовый файл в программе Блокнот и еще раз убедитесь в правильности распознавания. Закройте программу Блокнот.
Дайте команду Файл > Открыть и выберите изображение, созданное в предыдущем упражнении.
Выберите это изображение в окне Пакет и проведите его распознавание в соответствии с пп. 6-8 данного упражнения.
Сравните результаты распознавания при сканировании через TWAflV-драйвер и в обход его. Сравните трудоемкость этих операций.
1. Включите сканер.
Запустите программу Fine Reader (Пуск > Программы > ABBYY Fine Reader > Fine Reader 4.0 Professional).
Откройте крышку сканера, положите документ на окно сканера текстом вниз, закройте крышку.
Щелкните на кнопке Сканировать на панели инструментов Scan&Read и дождитесь окончания сканирования.
Щелкните на кнопке Сегментировать на панели инструментов Scan&Read.
Щелкните на кнопке Распознать на панели инструментов Scan&Read. Ознакомьтесь с тем, как проведено упорядочение распознанного текста в соответствии с автоматической сегментацией. Оцените пригодность полученного документа.
Закройте окно Текст. Полученный документ предварительно сохраните для сравнения.
Щелкните в окне Изображение правой кнопкой мыши и выберите в контекстном меню команду Удалить все блоки.
Сформируйте блоки вручную, выделяя отдельные элементы документа.
Чтобы блоки, содержащие иллюстрации, не распознавались как текст, щелкните на каждом из них правой кнопкой мыши и выберите в контекстном меню команду Тип блока > Картинка.
Щелкните на кнопке Перенумеровать блоки на панели Инструменты. Задайте последовательность блоков, щелкая на них в том порядке, в каком их содержимое должно включаться в окончательный документ.
Щелкните на кнопке Распознать на панели инструментов Scan&Read. Сохраните полученный документ.
Сравните документы, полученные в результате автоматической и ручной сегментации.
для распознавания бланков
Запустите программу FineReader Forms (Пуск > Программы > ABBYY FineReader > Fine Reader 4.0 Forms).
Откройте крышку сканера, положите бланк на окно сканера текстом вниз, закройте крышку.
Дайте команду Файл > Новый.
Задайте имя пакета и место его размещения, после чего щелкните на кнопке Далее.
Установите переключатель Создать новый и щелкните на кнопке Далее.
Введите имя шаблона и щелкните на кнопке Далее.
Установите переключатель Отсканировать и щелкните на кнопке Далее. Дождитесь окончания сканирования. Щелкните на кнопке Готово.
Создайте блоки, охватывающие постоянные поля («разметку») бланка. Для каждого такого блока на вкладке Блок диалогового окна параметры задайте тип Статический.
Создайте блоки, охватывающие переменные (заполняемые) поля бланка. Для каждого такого поля установите флажок Экспортируемый блок и задайте имя поля базы данных (Поле БД).
Завершив разметку бланка, щелкните на кнопке Закрыть на панели инструментов.
После закрытия редактора шаблонов снова отсканируйте тот же бланк, но уже для распознавания (кнопка Сканировать на панели инструментов Open&Read).
Щелкните на кнопке Наложить шаблон на панели инструментов Open&Read.
Щелкните на кнопке Распознать на панели инструментов Open&Read.
Ознакомьтесь с заполненной формой, полученной в результате распознавания. Сохраните документ в виде таблицы Excel.
17.2. Автоматизированный перевод документовК средствам автоматизации перевода можно отнести два вида программ: электронные словари и программы перевода. Электронные словари представляют собой средства для перевода отдельных слов, отображаемых на экране или имеющихся в документе. Удобство их использования состоит в возможности немедленно получить перевод неизвестного слова без поиска его в отдельном толстом томе. Программы перевода получают на входе текст, выполненный на одном языке, и выдают текст на другом языке, то есть автоматизируют перевод текста.
Электронные словари удобны для профессиональных переводчиков, которые выполняют большую часть работы по переводу вручную. Их также могут использовать лица, в целом знающие иностранный язык, если надо не обеспечить перевод документа, а просто ознакомиться с его содержанием.
Надежный и качественный автоматический перевод документов с одного языка на другой (мы будем говорить в основном о переводе с английского на русский) пока остается недостижимым идеалом. Причин для этого множество, и главная из них состоит в том, что перевод текста не сводится к переводу отдельных лексических единиц. Преодолеть этот барьер современные программы автоматического перевода пока не могут.
Тем не менее, современные средства автоматизации перевода достигли того уровня, который позволяет эффективно использовать их на практике. Дело в том, что технический текст, в отличие от художественного, использует ограниченное число языковых конструкций и более ориентирован на однозначную интерпретацию. Среди используемых лексических единиц встречается большое число технических терминов, имеющих совершенно определенный смысл в рамках данной научной или технической дисциплины. Это значительно упрощает процесс перевода и позволяет в отдельных случаях автоматически получать текст, близкий к результату ручного подстрочного перевода.
Программы автоматического перевода имеет смысл использовать для перевода технических текстов в следующих случаях:
при абсолютном незнании иностранного языка;
при необходимости получить перевод быстро, даже ценой снижения его качества (например, это относится к переводу Web-документов);
для перевода на иностранный язык (умения читать иноязычные тексты недоста точно, чтобы научиться объясняться на иностранном языке);
для быстрого создания первоначального черновика («подстрочника»), используемого в ходе подготовки полноценного перевода.
Работа с программой Promt 98
Для автоматизированного перевода технических текстов можно, например, использовать программу Promt 98. Она позволяет переводить документы с английского языка на русский и с русского на английский. Чтобы обеспечить правильный перевод терминов, относящихся к определенной научной дисциплине, используют специализированные словари, в которых для слов, используемых как термины, предлагается в качестве перевода не «обиходное», а специальное значение.
Если программа Promt 98 установлена на компьютере, для ее запуска можно использовать Главное меню (Пуск > Программы > Главное меню > PROMT 98 > PROMT 98), значок PROMT 98 на Рабочем столе или значок программы на панели индикации (команда PROMT 98 в контекстном меню этого значка).
Одновременно для обработки может быть открыто несколько документов. Окна документов имеют необычный вид (рис. 17.4). Они разбиваются на три отдельные области: две из них предназначены для отображения оригинала текста и сформированного перевода, а третья представляет собой информационную панель, предназначенную для вывода информации о переводимом документе и специальных настройках.

Рис. 17.4. Рабочее окно системы автоматизированного перевода Promt 98
Чтобы произвести перевод имеющегося документа с использованием заданных по умолчанию настроек, применяют следующий порядок действий.
Сначала необходимо открыть документ на языке оригинала (кнопка Открыть на панели инструментов Основная). Нужный документ выбирают в диалоговом окне Выберите документ. Формат открываемого файла выбирают в раскрывающемся списке Тип файлов.
После выбора файла появляется диалоговое окно Конвертировать файл. В нем можно уточнить реальный формат документа, хранящегося в файле, если он не соответствует типу файла или когда тип файла может соответствовать нескольким разным форматам документа.
Документ загружается и отображается в области исходного текста. При вертикальном разбиении окна документа эта область располагается слева. Если
предполагается длительная работа над переводом текста, его сохраняют как
документ программы Promt 98 (файл с расширением .STD).
Определение языков оригинала и перевода рассматривается как направление перевода. Чтобы выбрать направление перевода, используют кнопку Изменить направление на панели инструментов Перевод.
Чтобы перевести весь текст целиком, используют кнопку Весь текст на панели инструментов Перевод. В ходе выполнения перевода на экране отображается диалоговое окно Перевод текста с индикатором хода работы. Перевод текста помещается (при вертикальном разбиении окна) в правую область. Для удобства последующего редактирования перевод снабжается цветовой разметкой: неизвестные программе слова выделяются красным цветом, а зарезервированные слова, которые не надо переводить, — зеленым.
Текст, помещенный в областях окна программы Promt 98, можно редактировать (и оригинал, и перевод). Чтобы заново перевести отредактированный абзац, используют кнопку Текущий абзац на панели инструментов Перевод. Текущий абзац — это абзац, в котором располагается текстовый курсор. Он выделяется голубой полосой вдоль левого края.
6. После того как работа с документом в программе Promt 98 завершена, его сохраняют в одном из общепринятых форматов. Для сохранения только оригинала (возможно, отредактированного) служит команда Файл > Сохранить > Исходный текст. Чтобы сохранить переведенный текст, применяют команду Файл > Сохранить > Перевод. В обоих случаях можно сохранять как содержимое документа, так и его элементы форматирования, сохраняющие, по возможности, оформление оригинала.
Чтобы продолжить работу с текстом позднее, удобнее сохранить его двуязычный вариант, так называемую билингву (Файл > Сохранить > Билингву). Информация сохраняется в виде неформатированного текста, причем абзацы оригинала и перевода чередуются.
Контроль качества перевода
Качество перевода определяется полнотой используемых словарей и учетом грамматических правил. При переводе можно как применять стандартные ресурсы программы, так и добавлять собственные.
Работа со словарями. Правила перевода отдельных слов (терминов) определяются использованием словарей. Для каждого переводимого документа задается набор применяемых словарей. Словари просматриваются в определенном порядке, и, как только переводимое слово обнаружено в каком-то из словарей, дальнейший просмотр прекращается. Программа Promt 98 использует при переводе три типа словарей.
Генеральный словарь содержит общеупотребительную лексику и бытовые значения слов. Он используется всегда и притом самым последним, если слово не найдено ни в одном из других словарей. Изменение этого словаря невозможно.
Специализированные словари содержат термины из различных областей знаний, причем значение переводимого термина выбирается в соответствии со специализацией словаря. Одни и те же слова могут иметь совершенно разный смысл в разных технических дисциплинах, так что выбор нужного словаря обеспечивает правильное использование специальной терминологии в переводе. Редактирование специализированных словарей не допускается, но их можно подключать или отключать при переводе документа.
Пользовательский словарь формируется пользователем вручную. В него можно включить слова, отсутствующие в других словарях, или представить более точный перевод каких-то из терминов. Пользовательские словари можно произвольно создавать и редактировать. Применяют пользовательские словари обычно в первую очередь, до специализированных и генерального.
Узнать, какие словари используются при переводе, можно на вкладке Используемые словари на информационной панели. Порядок перечисленных словарей соответствует порядку их использования. Генеральный словарь в этом списке не указывается. Чтобы задать иной набор словарей или изменить их порядок, следует щелкнуть на соответствующей вкладке информационной панели правой кнопкой мыши и выбрать в контекстном меню пункт Изменить список словарей.
Настройка производится в диалоговом окне Словари. Чтобы отключить словарь, надо выбрать его в списке и щелкнуть на кнопке Отключить. Добавление словарей производится с помощью кнопки Подключить. Для создания нового пользовательского словаря служит кнопка Создать. Чтобы изменить порядок просмотра словарей, надо выбрать перемещаемый словарь и использовать для его передвижения по списку кнопки Вверх и Вниз.
Транслитерация и резервирование. Не все слова требуют перевода. Обычно без изменений оставляют имена собственные. Иногда при этом используют транслитерацию — запись, использующую другой алфавит, но соответствующую написанию или произношению слова на исходном языке. В частности, транслитерация повсеместно используется при передаче иностранных имен и фамилий. Транслитерация не считается переводом.
Иногда необходимо отказаться от перевода целых абзацев. Например, нелепый результат даст попытка перевода исходных текстов программ. То же самое можно сказать и обо всех других случаях, где используются не значения слов, а сами слова как ключевые.
Чтобы зарезервировать слово, его надо выделить и щелкнуть на кнопке Зарезервировать слово на панели инструментов Перевод. В открывшемся диалоговом окне Зарезервировать слово можно уточнить написание, указать смысловую категорию, к которой относится данный термин, а также установить флажок Транслитерировать, если нужна транслитерация. Все зарезервированные слова заносятся в список на вкладке Зарезервированные слова на информационной панели, а в самом документе выделяются зеленым цветом.
Чтобы указать на то, что абзац не требует перевода, надо установить текстовый курсор внутрь данного абзаца и щелкнуть на кнопке Оставить абзац без перевода на панели инструментов Перевод. Зарезервированный абзац также отображается зеленым цветом. Если резервирование слов или абзацев произведено после выполнения перевода, то для того, чтобы данные настройки вступили в силу, надо произвести перевод соответствующих абзацев заново.
Если приходится работать с тематически связанными документами или документом, разбитым на несколько отдельных файлов, следует использовать общий список зарезервированных слов. Чтобы сохранить список зарезервированных слов в отдельном файле, следует щелкнуть на вкладке Зарезервированные слова информационной панели правой кнопкой мыши и выбрать в контекстном меню пункт Сохранить список. Для загрузки такого автономного списка в документ используется команда Загрузить список из этого же контекстного меню.
Пополнение словаря. При автоматическом переводе реальных документов часто приходится сталкиваться со словами, которые программа перевода не смогла найти ни в одном из допустимых словарей. Эти слова заносятся в список на вкладке Незнакомые слова на информационной панели и выделяются в тексте документа красным цветом.
Слова могут быть неопознаны по разным причинам. В число их могут входить:
опечатки в оригинале документа;
для документов, преобразованных в электронную форму, ошибки распознавания;
собственные имена, требующие резервирования;
слова, отсутствующие в словарях.
В первых двух случаях необходимо отредактировать исходный текст, в третьем — зарезервировать слово и только в последнем случае необходимо занести слово в пользовательский словарь. При этом кроме собственно значения слова в переводе необходимо задать грамматические правила изменения форм этого слова и его сочетания с другими словами. В самом простом режиме работы (Начинающий) программа автоматически добавляет недостающие формы слова по заданному образцу.
Для того чтобы внести слово в словарь, надо выделить его и щелкнуть на кнопке Словарная статья на панели инструментов Перевод. В диалоговом окне Открыть словарную статью нужно указать начальную форму слова и выбрать словарь, в который будет внесено это слово. После этого откроется диалоговое окно Словарная статья, используемое для добавления слова (рис. 17.5).
Выберите вкладку, соответствующую нужной части речи, установите переключатели, описывающие свойства данного слова, и щелкните на кнопке Добавить. В диалоговом окне Перевод укажите перевод слова, также в начальной форме. Если откроется диалоговое окно Тип словоизменения, надо щелкнуть на имеющейся в нем кнопке (для глаголов она называется Спряжение) и указать, как выглядят запрашиваемые формы слова. В заключение может быть задан вопрос о том, для каких форм исходного слова применим данный перевод и как они выглядят.
Имеющиеся словари можно также просматривать и редактировать. Для этого надо дважды щелкнуть на названии словаря на вкладке Используемые словари на информационной панели. Словарь открывается, и на экран выводится список включенных в него слов. Дважды щелкнув на любом слове, можно отредактировать соответствующую словарную статью. Результаты такого редактирования всегда заносятся только в пользовательский словарь.

Рис. 17.5. Средство наполнения пользовательского словаря
Программа оптического распознавания текста (FineReader 7.0)
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ.
П роблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов. Реальный технический прорыв в этой области произошел лишь в последние годы. До этого распознавание текста было возможно только путем сравнения обнаруженных конфигураций точек со стандартным образцом (эталоном, хранящимся в памяти компьютера). Авторы программ задавали критерий «похожести», используемый при идентификации символов.
роблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов. Реальный технический прорыв в этой области произошел лишь в последние годы. До этого распознавание текста было возможно только путем сравнения обнаруженных конфигураций точек со стандартным образцом (эталоном, хранящимся в памяти компьютера). Авторы программ задавали критерий «похожести», используемый при идентификации символов.
Подобные системы назывались OCR (Optical Character Recognition — оптическое распознавание символов) и опирались на специально разработанные шрифты, облегчавшие такой подход. Естественно приходилось сталкиваться с произвольным и, тем более, сложным шрифтом, программы такого рода начинали давать серьезные сбои.
Современные научные достижения в области распознавания образов буквально перевернули представление об оптическом распознавании символов. Современные программы вполне могут справляться с различными (и весьма вычурными) шрифтами без перенастройки. Многие распознают даже рукописный текст.
Поскольку потребность в распознавании текста отсканированных документов достаточно велика, неудивительно, что имеется значительное число программ, предназначенных для этой цели. Так как разные научные методы распознавания текста развивались независимо друг от друга, многие из этих программ используют совершенно разные алгоритмы.
Эти алгоритмы могут давать разные результаты на разных документах. Например, упоминавшиеся выше системы OCR способны распознавать только стандартный специально подготовленный шрифт и дают на этом шрифте наилучшие результаты, которые не может превзойти ни одна, из более универсальных программ.
Современные алгоритмы распознавания текста не ориентируются ни на конкретный шрифт, ни на конкретный алфавит. Большинство программ способно распознавать текст на нескольких языках. Одни и те же алгоритмы можно использовать для распознавания русского, латинского, арабского и других алфавитов и даже смешанных текстов. Разумеется, программа должна знать, о каком алфавите идет речь.
Нас, прежде всего, интересуют программы, способные распознавать текст, напечатанный на русском языке. Такие программы выпускаются отечественными производителями. Наиболее широко известна и распространена программа FineReader. Мы подробно остановимся именно на этой программе, обеспечивающей высокое качество распознавания и удобство применения.
Программа FineReader выпускается отечественной компанией ABBYY Software (www.bitsoft.ru ). Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках, а также для распознавания смешанных текстов.
Программа имеет ряд удобных возможностей. Она позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (или с многостраничными документами) и с бланками. Программу можно обучать для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов. Она позволяет редактировать распознанный текст и проверять его орфографию.
FineReader работает с разными моделями сканеров. В частности, программа поддерживает стандарт TWAIN. Мы рассмотрим программу на примере версии 7.0
Распознавание документов в программе FineReader

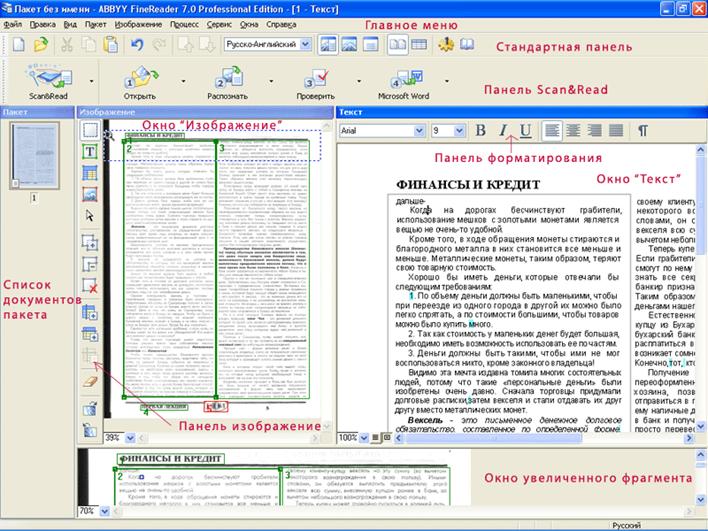
После установки программы FineReader в меню Программ Главного меню появляются пункты, обеспечивающие работу с ней. Окно программы имеет типичный для приложений Windows вид и содержит строку меню, ряд панелей инструментов и рабочую область.
В левой части рабочей области располагается панель Пакет, содержащая список графических документов, которые должны быть преобразованы в текст. Эти графические файлы рассматриваются как части одного документа. Результаты их обрабатываются и в дальнейшем объединяются в единый текстовый файл. Форма значка, отмечающего исходные файлы, указывает, было ли произведено распознавание.
Панель в нижней части рабочей области содержит фрагмент графического документа в увеличенном виде. С ее помощью можно оценить качество распознавания. Эту панель используют также при «обучении» программы в ходе распознавания.
Остальную часть рабочей области занимают окна документа. Здесь располагается окно графического документа, подлежащего распознаванию, а также окно текстового документа, полученного после распознавания.
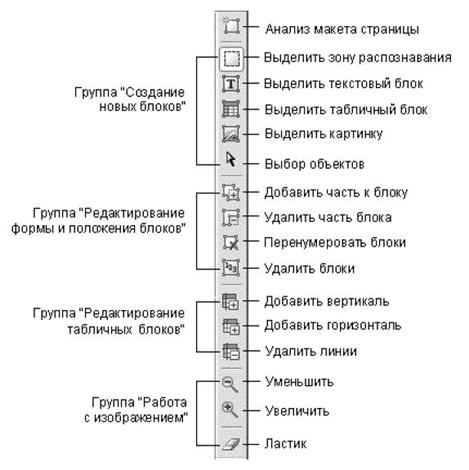
В верхней части окна приложения под строкой меню располагаются панели инструментов. На приведенном рисунке включено отображение всех панелей, которые могут быть использованы в программе FineReader.
Панель инструментов Стандартная содержит кнопки для открытия документов и для операций с буфером обмена. Прочие кнопки этой панели служат для изменения рабочей зоны.
Панель Scan&Read содержит кнопки, соответствующие этапам превращения бумажного документа в электронный текст. Первая кнопка позволяет выполнить такое преобразование в рамках единой операции. Остальные кнопки соответствуют отдельным этапам работы и содержат раскрывающиеся меню, служащие для управления соответствующей операцией.
Панель Изображение используют при работе с исходным изображением. В частности, она позволяет управлять сегментацией документа. С помощью элементов управления этой панели задают последовательность фрагментов текста в итоговом документе.
Элементы управления панели Форматирование используют для изменения представления готового текста или при его редактировании.
Как ввести документ за минуту
Включите сканер (если он имеет отдельный от компьютера источник питания).
Внимание! Многие модели сканера необходимо включать до включения компьютера.
Вставьте в сканер страницу, которую Вы хотите распознать.
Нажмите на стрелку справа от кнопки Scan&Read. в открывшемся локальном меню выберите пункт Мастер Scan&Read.
М астер Scan&Read вызывает специальный режим, при котором Вы можете отсканировать и распознать страницу или открыть и распознать графическое изображение (пример графического файла Вы можете найти в папке Dio. Она находится в папке, в которую Вы установили FineReader). При этом каждый шаг сопровождается подсказками системы.
астер Scan&Read вызывает специальный режим, при котором Вы можете отсканировать и распознать страницу или открыть и распознать графическое изображение (пример графического файла Вы можете найти в папке Dio. Она находится в папке, в которую Вы установили FineReader). При этом каждый шаг сопровождается подсказками системы.
Далее следуйте указаниям Мастера Scan&Read.
Процесс ввода документов в компьютер состоит из четырех этапов: сканирования, распознавания, проверки и сохранения результатов распознавания.
В результате сканирования появится окно Изображение, содержащее "фотографию" страницы. Затем программа попросит Вас установить параметры распознавания и приступит к распознаванию изображения, одновременно анализируя его. Обработанные участки изображения закрашиваются голубым цветом.
Результат распознавания Вы увидите в окне Текст. В этом же окне Вы можете проверить и отредактировать распознанный текст. Следуя далее указаниям Мастера Scan&Read, Вы можете либо передать распознанный текст в выбранное Вами приложение или сохранить его на диске, либо продолжить обработку следующих изображений.
Используйте разрешение 300 dpi для стандартных текстов (размер шрифта 10pts. и больше) и разрешение 400-600 dpi для текстов с меньшим шрифтом (9pts. и меньше). Сканирование в сером режиме рекомендуется для повышения качества распознавания. При сканировании в сером режиме яркость регулируется автоматически. Если Вы хотите, чтобы диалог Настройки сканера открывался каждый раз перед сканированием при работе в режиме - Использовать интерфейс FineReader. Меню Сервис — Опции - на закладке Сканирование / отметьте опцию - Запрашивать опции перед началом сканирования.
Анализ оформления страницы
Анализ оформления страницы может проходить как вручную, так и автоматически. В большинстве случаев программа FineReader сама выполняет сложную задачу анализа страницы. Нажмите кнопку Распознать для запуска автоматического анализа оформления страницы. Распознавание и анализ страницы выполняются одновременно.
Если программа выделила некоторые блоки неправильно, проще и быстрее редактировать неправильно размеченные блоки, используя инструмент для редактирования блоков, чем удалять блоки и выделять их заново вручную.
В некоторых случаях качество автоматического анализа страницы может быть улучшено с помощью изменения опций анализа оформления страницы. Для просмотра текущих опций страницы меню Сервис — Опции / закладка Распознавание.
Улучшение качества распознавания изображений сдвоенных страниц
Чтобы увеличить качество распознавания, разбейте сканируемые изображения так, чтобы каждой из пары сдвоенных страниц на изображении соответствовала отдельная страница пакета. Изображения могут быть разбиты как автоматически, так и вручную.
Чтобы разбивать изображения автоматически перед добавлением в пакет на стрелке возле кнопки Сканирование /Открыть в диалоге Опции. отметьте опцию - Делить разворот книги. Чтобы разбивать изображения вручную, отметьте опцию - Разбить изображение в меню Изображение. Устранение искажений, анализ оформления страницы и распознавание будут проходить отдельно для каждой страницы.
Неправильно отображаемые символы
Если в окне Текст программы FineReader символы отображаются неправильно (например, "?" или "?" на месте некоторых букв), это означает, что текущий шрифт не поддерживает полностью алфавит выбранного Вами языка распознавания. Выберите шрифт, который поддерживает все символы текста распознаваемой страницы (например, Arial Unicode или Bitstream Cyberbit) на закладке Форматирование (меню Свойства — Опции ) в группе Шрифты. и распознайте документ заново.
Редактирование распознанного текста в Microsoft Word
Если Вы предпочитаете редактировать распознанный текст в Microsoft Word, а не в текстовом окне программы FineReader, Вы можете сделать так, чтобы неуверенно распознанные символы остались подсвеченными. В меню Сервис выберите пункт Форматы - на закладке RTF/DOC/Word XML отметьте опцию Цветом фона и/или Цветом символа в группе - Выделять неуверенно распознанные символы. В сохраненном файле все неуверенно распознанные символы будут подсвечены выбранными Вами на этой закладке цветами.
Теперь давайте остановимся немного подробнее на панелях программы и правилах работы с программой.
Главная панель программы Scan&Read
М астер Scan&Read - запускает специальный режим сканирования и распознавания, во время которого система контролирует действия пользователя и подсказывает ему, что надо делать, чтобы получить тот или иной результат. Сканировать и распознать - запускает сканирование и распознавание документа. Сканировать и распознать несколько страниц - сканирует и распознает несколько страниц в цикле.
астер Scan&Read - запускает специальный режим сканирования и распознавания, во время которого система контролирует действия пользователя и подсказывает ему, что надо делать, чтобы получить тот или иной результат. Сканировать и распознать - запускает сканирование и распознавание документа. Сканировать и распознать несколько страниц - сканирует и распознает несколько страниц в цикле.
Открыть и распознать - позволяет открыть и распознать изображения, выбранные в диалоге Открыть (Open).
О ткрыть изображение - добавляет изображение в пакет, при этом копия изображения сохраняется в папке пакета.
ткрыть изображение - добавляет изображение в пакет, при этом копия изображения сохраняется в папке пакета.
Сканировать изображение - сканирует изображение. Сканировать несколько страниц - сканирует изображения в цикле. Чтобы остановить сканирование, в меню Файл выберите пункт Остановить сканирование. Опции - открывает закладку Сканирование/Открытие диалога Опции, на которой Вы может установить опции сканирования и предварительной обработки документа.

Распознать - распознает открытую страницу (или выделенные страницы) пакета.
Распознать все - распознает все нераспознанные страницы пакета.
Опции - открывает закладку Распознавание диалога
Опции, на которой Вы может установить опции распознавания документа.
Проверить - позволяет найти в тексте слова, содержащие неуверенно распознанные символы, и неправильно написанные слова.
О пции - открывает закладку Проверка диалога Опции, на которой Вы можете установить опции проверки документа.
пции - открывает закладку Проверка диалога Опции, на которой Вы можете установить опции проверки документа.

Мастер сохранения результатов - открывает диалог Мастер сохранения результатов, в котором Вы можете выбрать приложение для сохранения и установить опции сохранения.
Сохранить текст в файл - сохраняет распознанный текст в файл на диск.
Передать страницы в - напрямую передает распознанный текст в выбранное приложение без сохранения его на диск. При передаче распознанного текста с нескольких страниц пакета сначала выделите их в окне Пакет.
Передать все страницы в - передает все распознанные страницы в выбранное приложение без сохранения их на диск.
Опции - открывает закладку Форматирование диалога Опции, на которой Вы можете установить опции сохранения документа.



Советы и примеры
Одним из наиболее популярных форматов представления электронных документов в Internet, архивах и т.д. является формат PDF (Portable Document Format ).
Открыв PDF-файл в FineReader, Вы можете его распознать, отредактировать и сохранить либо в PDF, выбрав один из четырех режимов сохранения оформления документа (только текст и картинки, только изображение, текст поверх изображения картинки, текст под изображением картинки), либо в любом другом поддерживаемом формате сохранения.
Чтобы установить режимы сохранения в формате PDF:
В меню Сервис выберите пункт Форматы.
На закладке PDF диалога Форматы установите требуемый режим.
PDF является распространенным форматом для пересылки документов по электронной почте или публикации документов на web-сайтах. Естественно, что при публикации на web-сайтах очень важна высокая скорость открытия документов. Документ, сохраненный из программы FineReader в формате PDF, отвечает подобным требованиям. Структура PDF такова, что позволяет открывать в пользовательском браузере для просмотра первые страницы PDF документа, не дожидаясь, когда весь файл целиком будет загружен с web-сервера.
Сложная журнальная страница
О писание ситуации: плохое качество распознавания вследствие неправильного выделения блоков.
писание ситуации: плохое качество распознавания вследствие неправильного выделения блоков.
Решение. В результате автоматического анализа данной страницы были выделены лишние блоки (например, участки текста на картинке). Проверьте количество блоков, а также отредактируйте форму выделенных блоков.
Для этого воспользуйтесь инструментами на панели Изображение.
 - чтобы удалить выделенные на картинке лишние блоки текста или предварительно, выделив блок, нажмите на клавиатуре кнопку Delete;
- чтобы удалить выделенные на картинке лишние блоки текста или предварительно, выделив блок, нажмите на клавиатуре кнопку Delete;
 и
и  - чтобы нарисовать текстовый блок и блок-картинку, либо нарисуйте блок самостоятельно, как если вы рисовали просто прямоугольник в графическом редакторе и в контекстном меню (правой кнопкой мыши на блоке) выберите тип требуемого блока.
- чтобы нарисовать текстовый блок и блок-картинку, либо нарисуйте блок самостоятельно, как если вы рисовали просто прямоугольник в графическом редакторе и в контекстном меню (правой кнопкой мыши на блоке) выберите тип требуемого блока.
Замечание: При выделении текстовых блоков следите за тем, чтобы границы блоков совпадали с границами текста.
Описание ситуации: за одно сканирование сканируется пара страниц (книжный разворот), при этом каждая страница имеет свой угол наклона, что отрицательно сказывается на качестве распознавания, кроме того, обе страницы сохраняются на одну страницу в две колонки.
( DualPage.tif) При распознавании изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз, и строки должны быть горизонтальными. По умолчанию при распознавании программа автоматически определяет и корректирует ориентацию изображения. У изображений со сдвоенными страницами стандартная ориентация отсутствует, так как каждая страница имеет свой угол наклона.
DualPage.tif) При распознавании изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз, и строки должны быть горизонтальными. По умолчанию при распознавании программа автоматически определяет и корректирует ориентацию изображения. У изображений со сдвоенными страницами стандартная ориентация отсутствует, так как каждая страница имеет свой угол наклона.
Решение. В программе существует специальный режим, при котором изображение со сдвоенными страницами разрезается на две части и превращается в две отдельные страницы пакета. Это позволяет обработать каждую страницу: автоматически исправить угол наклона и сохранить распознанный текст с каждой страницы в отдельный файл (или на отдельную страницу).
Чтобы установить данный режим,перед добавлением изображения в пакет на закладке Сканирование/Открытие в группе Обработка изображений отметьте опцию - Делить книжный разворот.
Разрезать изображение со сдвоенными страницами на две части, которые впоследствии будут преобразованы в две отдельные страницы пакета, можно также с помощью опции - Разбить изображение.
Конечно, это очень удобно - вся важная информация о человеке сконцентрирована на листке бумаги небольшого формата. Но иногда пугает их количество, и мы тратим массу времени для того, чтобы их упорядочить, привести в систему, найти удобное средство хранения.
Удобный способ ввода и хранения визиток в компьютере с помощью программы FineReader. Все визитки обрабатываются и хранятся в пакете программы. Используя функцию полнотекстового поиска по распознанным страницам пакета, Вы можете найти нужную визитку (при этом поиск возможен по любой распознанной информации с визитки - по названию компании, фамилии, телефону и т.д.). Список найденных визиток показывается в окне Поиск. Чтобы открыть визитку, выберите запись в результатах поиска.
Вы можете пополнять пакет новыми визитками, редактировать уже распознанные визитки в окне Текст.
Положите несколько визитных карточек (столько, сколько уместится) в сканер.
Внимание! Визитки должны быть разложены так, чтобы в результате была получена "табличная структура". Между рядами и колонками должно быть некоторое расстояние. Допустимо либо горизонтальное (более длинные стороны визиток расположены вдоль горизонтали), либо вертикальное размещение визиток на листе, но не оба сразу.
Установите следующие параметры сканирования:
разрешение - 400-600 dpi (обычно визитные карточки содержат текст, набранный мелким шрифтом, для хорошего распознавания которого требуется отсканировать документ с более высоким разрешением вместо обычных 300 dpi).
тип изображения - серый или цветной.
Нажмите кнопку - Сканировать.
Для повышения качества распознавания, полученные изображения с визитками следует разделить так, чтобы каждой визитке соответствовала отдельная страница пакета. В этом случае исправление перекоса строк, анализ и распознавание будет проводиться для каждой визитки. Для этого в меню Изображение выберите пункт - Разбить изображение. В открывшемся диалоге - Разбить изображение нажмите кнопку  . а затем кнопку ОК. В окне Пакет появятся новые страницы: каждая страница будет содержать изображение одной визитки. При этом исходное изображение (содержащее несколько визиток) будет удалено из пакета.
. а затем кнопку ОК. В окне Пакет появятся новые страницы: каждая страница будет содержать изображение одной визитки. При этом исходное изображение (содержащее несколько визиток) будет удалено из пакета.
Замечание. Если изображение было поделено на визитки неверно, то попробуйте поделить изображение вручную. Для этого воспользуйтесь кнопками  и
и . Чтобы передвинуть или удалить разделитель, нажмите кнопку Выбор разделителя -
. Чтобы передвинуть или удалить разделитель, нажмите кнопку Выбор разделителя -  . мышью переместите разделитель в нужное место. Для удаления разделителя переместите его за границы изображения. Чтобы удалить все разделители, нажмите кнопку
. мышью переместите разделитель в нужное место. Для удаления разделителя переместите его за границы изображения. Чтобы удалить все разделители, нажмите кнопку  .
.
Установите язык распознавания. Если требуется, установите несколько языков. При этом помните, что увеличение количества подключенных к распознаванию одного документа языков может привести к ухудшению качества распознавания. Не рекомендуется подключать более 2-3 языков. Перед запуском распознавания проверьте подключенные на закладке Форматирование шрифты: они должны содержать все символы языка распознавания. В противном случае распознанный текст будет неправильно отображен в окне Текст (в словах на месте некоторых букв стоят значки "?" или "?").
Нажмите кнопку - Распознать.
Программная распечатка
Описание ситуации: данный пример имеет две особенности, влияющие на качество распознавания:
программа передает отступы от левого края листа не пробелами, а с помощью задания отступов абзаца; при экспорте в .txt левый отступ не сохраняется; некоторые строки объединяются в один абзац и при экспорте объединяются в одну строку;
много ошибок при распознавании конструкций языков программирования.
Для распознавания таких документов существует специальная опция программы Форматированный пробелами текст. Устанавливается в группе Тип страницы на закладке Распознавание диалога Опции (меню Сервис — Опции ).
В этом случае в распознанном тексте сохранится деление на строки; отступы от левого края будут переданы пробелами; каждая строка выделена в отдельный абзац, а расстояния между абзацами переданы пустыми строками. Все это позволит сохранить исходное форматирование текста при сохранении в формате Txt.
Для хорошего распознавания распечаток программ требуется установить специальный язык распознавания. Для этого:
В списке языков на панели - Стандартная выберите значение Выбор из полного списка языков и в открывшемся диалоге Язык распознаваемого текста выберите пункт C++.
Замечание: Если распознаваемая программная распечатка помимо программного кода содержит текстовые комментарии, то для хорошего распознавания необходимо выбрать несколько языков распознавания: язык программирования и язык, на котором написаны комментарии.
Т аблица с неполным количеством черных разделителей
аблица с неполным количеством черных разделителей
Описание ситуации: все строки таблицы между черными горизонтальными линиями (разделителями) объединены в одну строку таблицы.
Если в таблице встречается смешанное разделение на строки и столбцы, при котором некоторые строки разделены черными разделителями, а некоторые нет, программа может разбить таблицу на строки неправильно.
Решение. Программу можно "заставить" выделять каждую строку текста в отдельную строку таблицы, отметив специальную опцию на закладке Распознавание (меню Сервис — Опции ) в группе Таблицы. В каждой ячейке таблицы не более одной строки текста.
Сложная таблица
О писание ситуации: неправильный анализ таблиц со сложной нерегулярной структурой: неправильное разделение таблицы на строки и столбцы; неправильное выделение картинок в ячейках таблицы; плохое распознавание вертикального и инвертированного текста.
писание ситуации: неправильный анализ таблиц со сложной нерегулярной структурой: неправильное разделение таблицы на строки и столбцы; неправильное выделение картинок в ячейках таблицы; плохое распознавание вертикального и инвертированного текста.
Решение. Воспользуйтесь инструментами ручной разметки таблиц, расположенными на панели Изображение.  - чтобы добавить вертикальную линию;
- чтобы добавить вертикальную линию;  - чтобы добавить горизонтальную линию;
- чтобы добавить горизонтальную линию;  - чтобы удалить линию.
- чтобы удалить линию.
Для ячеек таблицы, содержащих только картинки, в диалоге Свойства блока (меню Вид — Свойства ), отметьте пункт - Считать ячейку картинкой.
Для выделения картинок внутри ячеек с текстом в отдельные блоки, воспользуйтесь инструментом на панели Изображение. .
Для ячеек таблицы, содержащих вертикальный текст, в диалоге Свойства блока (меню Вид — Свойства ) в поле Направление текста укажите направление текста в ячейке; для ячеек с инвертированным текстом отметьте пункт Инвертированный.
Программа оптического распознавания текста (FineReader 7.0)
После обработки документа сканером получается графическое изображение документа (графический образ). Но графический образ еще не является текстовым документом. Человеку достаточно взглянуть на лист бумаги с текстом, чтобы понять, что на нем написано. С точки зрения компьютера, документ после сканирования превращается в набор разноцветных точек, а вовсе не в текстовый документ. Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов. Реальный технический прорыв в этой области произошел лишь в последние годы. До этого распознавание текста было возможно только путем сравнения обнаруженных конфигураций точек со стандартным образцом (эталоном, хранящимся в памяти компьютера). Авторы программ задавали критерий «похожести», используемый при идентификации символов.
Проблема распознавания текста в составе точечного графического изображения является весьма сложной. Подобные задачи решают с помощью специальных программных средств, называемых средствами распознавания образов. Реальный технический прорыв в этой области произошел лишь в последние годы. До этого распознавание текста было возможно только путем сравнения обнаруженных конфигураций точек со стандартным образцом (эталоном, хранящимся в памяти компьютера). Авторы программ задавали критерий «похожести», используемый при идентификации символов.
Подобные системы назывались OCR (Optical Character Recognition — оптическое распознавание символов) и опирались на специально разработанные шрифты, облегчавшие такой подход. Естественно приходилось сталкиваться с произвольным и, тем более, сложным шрифтом, программы такого рода начинали давать серьезные сбои.
Современные научные достижения в области распознавания образов буквально перевернули представление об оптическом распознавании символов. Современные программы вполне могут справляться с различными (и весьма вычурными) шрифтами без перенастройки. Многие распознают даже рукописный текст.
Поскольку потребность в распознавании текста отсканированных документов достаточно велика, неудивительно, что имеется значительное число программ, предназначенных для этой цели. Так как разные научные методы распознавания текста развивались независимо друг от друга, многие из этих программ используют совершенно разные алгоритмы.
Эти алгоритмы могут давать разные результаты на разных документах. Например, упоминавшиеся выше системы OCR способны распознавать только стандартный специально подготовленный шрифт и дают на этом шрифте наилучшие результаты, которые не может превзойти ни одна, из более универсальных программ.
Современные алгоритмы распознавания текста не ориентируются ни на конкретный шрифт, ни на конкретный алфавит. Большинство программ способно распознавать текст на нескольких языках. Одни и те же алгоритмы можно использовать для распознавания русского, латинского, арабского и других алфавитов и даже смешанных текстов. Разумеется, программа должна знать, о каком алфавите идет речь.
Нас, прежде всего, интересуют программы, способные распознавать текст, напечатанный на русском языке. Такие программы выпускаются отечественными производителями. Наиболее широко известна и распространена программа FineReader. Мы подробно остановимся именно на этой программе, обеспечивающей высокое качество распознавания и удобство применения.
Программа FineReader выпускается отечественной компанией ABBYY Software (www.bitsoft.ru ). Эта программа предназначена для распознавания текстов на русском, английском, немецком, украинском, французском и многих других языках, а также для распознавания смешанных текстов.
Программа имеет ряд удобных возможностей. Она позволяет объединять сканирование и распознавание в одну операцию, работать с пакетами документов (или с многостраничными документами) и с бланками. Программу можно обучать для повышения качества распознавания неудачно напечатанных текстов или сложных шрифтов. Она позволяет редактировать распознанный текст и проверять его орфографию.
FineReader работает с разными моделями сканеров. В частности, программа поддерживает стандарт TWAIN. Мы рассмотрим программу на примере версии 7.0
Распознавание документов в программе FineReader
После установки программы FineReader в меню Программ Главного меню появляются пункты, обеспечивающие работу с ней. Окно программы имеет типичный для приложений Windows вид и содержит строку меню, ряд панелей инструментов и рабочую область.
Как ввести документ за минуту
Мастер Scan&Read вызывает специальный режим, при котором Вы можете отсканировать и распознать страницу или открыть и распознать графическое изображение (пример графического файла Вы можете найти в папке Dio. Она находится в папке, в которую Вы установили FineReader). При этом каждый шаг сопровождается подсказками системы.
Далее следуйте указаниям Мастера Scan&Read.
Процесс ввода документов в компьютер состоит из четырех этапов: сканирования, распознавания, проверки и сохранения результатов распознавания.
В результате сканирования появится окно Изображение, содержащее "фотографию" страницы. Затем программа попросит Вас установить параметры распознавания и приступит к распознаванию изображения, одновременно анализируя его. Обработанные участки изображения закрашиваются голубым цветом.
Результат распознавания Вы увидите в окне Текст. В этом же окне Вы можете проверить и отредактировать распознанный текст. Следуя далее указаниям Мастера Scan&Read, Вы можете либо передать распознанный текст в выбранное Вами приложение или сохранить его на диске, либо продолжить обработку следующих изображений.
Используйте разрешение 300 dpi для стандартных текстов (размер шрифта 10pts. и больше) и разрешение 400-600 dpi для текстов с меньшим шрифтом (9pts. и меньше). Сканирование в сером режиме рекомендуется для повышения качества распознавания. При сканировании в сером режиме яркость регулируется автоматически. Если Вы хотите, чтобы диалог Настройки сканера открывался каждый раз перед сканированием при работе в режиме - Использовать интерфейс FineReader. Меню Сервис — Опции - на закладке Сканирование / отметьте опцию - Запрашивать опции перед началом сканирования.
Анализ оформления страницы может проходить как вручную, так и автоматически. В большинстве случаев программа FineReader сама выполняет сложную задачу анализа страницы. Нажмите кнопку Распознать для запуска автоматического анализа оформления страницы. Распознавание и анализ страницы выполняются одновременно.
Если программа выделила некоторые блоки неправильно, проще и быстрее редактировать неправильно размеченные блоки, используя инструмент для редактирования блоков, чем удалять блоки и выделять их заново вручную.
В некоторых случаях качество автоматического анализа страницы может быть улучшено с помощью изменения опций анализа оформления страницы. Для просмотра текущих опций страницы меню Сервис — Опции / закладка Распознавание .
Чтобы увеличить качество распознавания, разбейте сканируемые изображения так, чтобы каждой из пары сдвоенных страниц на изображении соответствовала отдельная страница пакета. Изображения могут быть разбиты как автоматически, так и вручную.
Чтобы разбивать изображения автоматически перед добавлением в пакет на стрелке возле кнопки Сканирование /Открыть в диалоге Опции. отметьте опцию - Делить разворот книги. Чтобы разбивать изображения вручную, отметьте опцию - Разбить изображение в меню Изображение. Устранение искажений, анализ оформления страницы и распознавание будут проходить отдельно для каждой страницы.
Если в окне Текст программы FineReader символы отображаются неправильно (например, "?" или "?" на месте некоторых букв), это означает, что текущий шрифт не поддерживает полностью алфавит выбранного Вами языка распознавания. Выберите шрифт, который поддерживает все символы текста распознаваемой страницы (например, Arial Unicode или Bitstream Cyberbit) на закладке Форматирование (меню Свойства — Опции ) в группе Шрифты. и распознайте документ заново.
Если Вы предпочитаете редактировать распознанный текст в Microsoft Word, а не в текстовом окне программы FineReader, Вы можете сделать так, чтобы неуверенно распознанные символы остались подсвеченными. В меню Сервис выберите пункт Форматы - на закладке RTF/DOC/Word XML отметьте опцию Цветом фона и/или Цветом символа в группе - Выделять неуверенно распознанные символы. В сохраненном файле все неуверенно распознанные символы будут подсвечены выбранными Вами на этой закладке цветами.
Теперь давайте остановимся немного подробнее на панелях программы и правилах работы с программой.
Главная панель программы Scan&Read
Мастер Scan&Read - запускает специальный режим сканирования и распознавания, во время которого система контролирует действия пользователя и подсказывает ему, что надо делать, чтобы получить тот или иной результат. Сканировать и распознать - запускает сканирование и распознавание документа. Сканировать и распознать несколько страниц - сканирует и распознает несколько страниц в цикле.
Открыть и распознать - позволяет открыть и распознать изображения, выбранные в диалоге Открыть (Open).
Открыть изображение - добавляет изображение в пакет, при этом копия изображения сохраняется в папке пакета.
Сканировать изображение - сканирует изображение. Сканировать несколько страниц - сканирует изображения в цикле. Чтобы остановить сканирование, в меню Файл выберите пункт Остановить сканирование. Опции - открывает закладку Сканирование/Открытие диалога Опции, на которой Вы может установить опции сканирования и предварительной обработки документа.
Распознать - распознает открытую страницу (или выделенные страницы) пакета.
Распознать все - распознает все нераспознанные страницы пакета.
Опции - открывает закладку Распознавание диалога
Опции, на которой Вы может установить опции распознавания документа.
Проверить - позволяет найти в тексте слова, содержащие неуверенно распознанные символы, и неправильно написанные слова.
Опции - открывает закладку Проверка диалога Опции, на которой Вы можете установить опции проверки документа.
Мастер сохранения результатов - открывает диалог Мастер сохранения результатов, в котором Вы можете выбрать приложение для сохранения и установить опции сохранения.
Сохранить текст в файл - сохраняет распознанный текст в файл на диск.
Передать страницы в - напрямую передает распознанный текст в выбранное приложение без сохранения его на диск. При передаче распознанного текста с нескольких страниц пакета сначала выделите их в окне Пакет.
Передать все страницы в - передает все распознанные страницы в выбранное приложение без сохранения их на диск.
Опции - открывает закладку Форматирование диалога Опции, на которой Вы можете установить опции сохранения документа.

Одним из наиболее популярных форматов представления электронных документов в Internet, архивах и т.д. является формат PDF (Portable Document Format ).
Открыв PDF-файл в FineReader, Вы можете его распознать, отредактировать и сохранить либо в PDF, выбрав один из четырех режимов сохранения оформления документа (только текст и картинки, только изображение, текст поверх изображения картинки, текст под изображением картинки), либо в любом другом поддерживаемом формате сохранения.
Чтобы установить режимы сохранения в формате PDF:
PDF является распространенным форматом для пересылки документов по электронной почте или публикации документов на web-сайтах. Естественно, что при публикации на web-сайтах очень важна высокая скорость открытия документов. Документ, сохраненный из программы FineReader в формате PDF, отвечает подобным требованиям. Структура PDF такова, что позволяет открывать в пользовательском браузере для просмотра первые страницы PDF документа, не дожидаясь, когда весь файл целиком будет загружен с web-сервера.
Сложная журнальная страница
Описание ситуации: плохое качество распознавания вследствие неправильного выделения блоков.
Решение. В результате автоматического анализа данной страницы были выделены лишние блоки (например, участки текста на картинке). Проверьте количество блоков, а также отредактируйте форму выделенных блоков.
Для этого воспользуйтесь инструментами на панели Изображение :
Замечание: При выделении текстовых блоков следите за тем, чтобы границы блоков совпадали с границами текста.
Описание ситуации: за одно сканирование сканируется пара страниц (книжный разворот), при этом каждая страница имеет свой угол наклона, что отрицательно сказывается на качестве распознавания, кроме того, обе страницы сохраняются на одну страницу в две колонки.
(DualPage.tif) При распознавании изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз, и строки должны быть горизонтальными. По умолчанию при распознавании программа автоматически определяет и корректирует ориентацию изображения. У изображений со сдвоенными страницами стандартная ориентация отсутствует, так как каждая страница имеет свой угол наклона.
Решение. В программе существует специальный режим, при котором изображение со сдвоенными страницами разрезается на две части и превращается в две отдельные страницы пакета. Это позволяет обработать каждую страницу: автоматически исправить угол наклона и сохранить распознанный текст с каждой страницы в отдельный файл (или на отдельную страницу).
Разрезать изображение со сдвоенными страницами на две части, которые впоследствии будут преобразованы в две отдельные страницы пакета, можно также с помощью опции - Разбить изображение.
Конечно, это очень удобно - вся важная информация о человеке сконцентрирована на листке бумаги небольшого формата. Но иногда пугает их количество, и мы тратим массу времени для того, чтобы их упорядочить, привести в систему, найти удобное средство хранения.
Удобный способ ввода и хранения визиток в компьютере с помощью программы FineReader. Все визитки обрабатываются и хранятся в пакете программы. Используя функцию полнотекстового поиска по распознанным страницам пакета, Вы можете найти нужную визитку (при этом поиск возможен по любой распознанной информации с визитки - по названию компании, фамилии, телефону и т.д.). Список найденных визиток показывается в окне Поиск. Чтобы открыть визитку, выберите запись в результатах поиска.
Вы можете пополнять пакет новыми визитками, редактировать уже распознанные визитки в окне Текст.
Внимание! Визитки должны быть разложены так, чтобы в результате была получена "табличная структура". Между рядами и колонками должно быть некоторое расстояние. Допустимо либо горизонтальное (более длинные стороны визиток расположены вдоль горизонтали), либо вертикальное размещение визиток на листе, но не оба сразу.
Установите следующие параметры сканирования:
Нажмите кнопку - Сканировать.
Замечание. Если изображение было поделено на визитки неверно, то попробуйте поделить изображение вручную. Для этого воспользуйтесь кнопками и . Чтобы передвинуть или удалить разделитель, нажмите кнопку Выбор разделителя - , мышью переместите разделитель в нужное место. Для удаления разделителя переместите его за границы изображения. Чтобы удалить все разделители, нажмите кнопку .
Программная распечатка
Описание ситуации: данный пример имеет две особенности, влияющие на качество распознавания:
В этом случае в распознанном тексте сохранится деление на строки; отступы от левого края будут переданы пробелами; каждая строка выделена в отдельный абзац, а расстояния между абзацами переданы пустыми строками. Все это позволит сохранить исходное форматирование текста при сохранении в формате Txt.
Замечание: Если распознаваемая программная распечатка помимо программного кода содержит текстовые комментарии, то для хорошего распознавания необходимо выбрать несколько языков распознавания: язык программирования и язык, на котором написаны комментарии.
 Таблица с неполным количеством черных разделителей
Таблица с неполным количеством черных разделителей
Описание ситуации: все строки таблицы между черными горизонтальными линиями (разделителями) объединены в одну строку таблицы.
Если в таблице встречается смешанное разделение на строки и столбцы, при котором некоторые строки разделены черными разделителями, а некоторые нет, программа может разбить таблицу на строки неправильно.
Решение. Программу можно "заставить" выделять каждую строку текста в отдельную строку таблицы, отметив специальную опцию на закладке Распознавание (меню Сервис — Опции ) в группе Таблицы. В каждой ячейке таблицы не более одной строки текста.
Сложная таблица
Описание ситуации: неправильный анализ таблиц со сложной нерегулярной структурой: неправильное разделение таблицы на строки и столбцы; неправильное выделение картинок в ячейках таблицы; плохое распознавание вертикального и инвертированного текста.
Решение. Воспользуйтесь инструментами ручной разметки таблиц, расположенными на панели Изображение.
- чтобы добавить вертикальную линию;
- чтобы добавить горизонтальную линию;
- чтобы удалить линию.
Для ячеек таблицы, содержащих только картинки, в диалоге Свойства блока (меню Вид — Свойства ), отметьте пункт - Считать ячейку картинкой.
Для выделения картинок внутри ячеек с текстом в отдельные блоки, воспользуйтесь инструментом на панели Изображение. .
Для ячеек таблицы, содержащих вертикальный текст, в диалоге Свойства блока (меню Вид — Свойства ) в поле Направление текста укажите направление текста в ячейке; для ячеек с инвертированным текстом отметьте пункт Инвертированный .